ロゴ.png)


今回はミッドジャーニー(Midjourney)で、自分が思った通りの絵を作る方法について解説します。
テキストプロンプトだけではどうしてもAIに伝わらず、イメージと違った画像が作られることが少なくないと思います。
そこである方法を試すと、構図や登場人物の詳細について理想に近づけることが出来ます。
この方法は2022年から発見されていたやり方ですが、いまだに使えると思いますのでご紹介します。

簡単な絵を描く
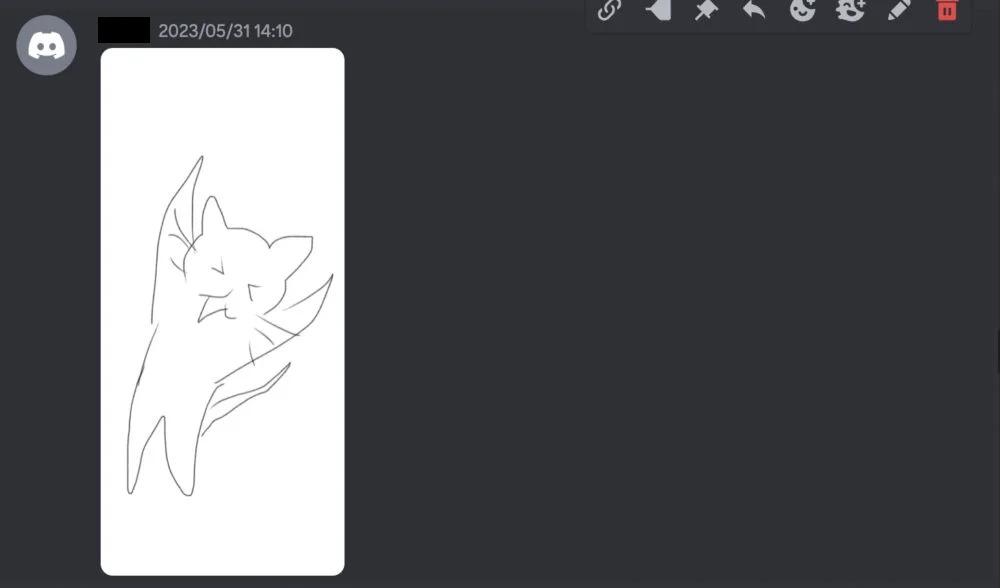
自身が思い描いている絵を、まずは簡単に描いてみましょう。
ペンタブレットを使用してもいいですが、スマホのペイントアプリで本当に簡単に描いても大丈夫です。

上図は私がスマホと指を使って描いたイラストです。
猫が両手を挙げてあくびをしている絵が欲しかったので、それを描きました。

ディスコードに送って画像URLを取得する
先ほどの画像をMidjourney BotがいるDiscordに送ります。
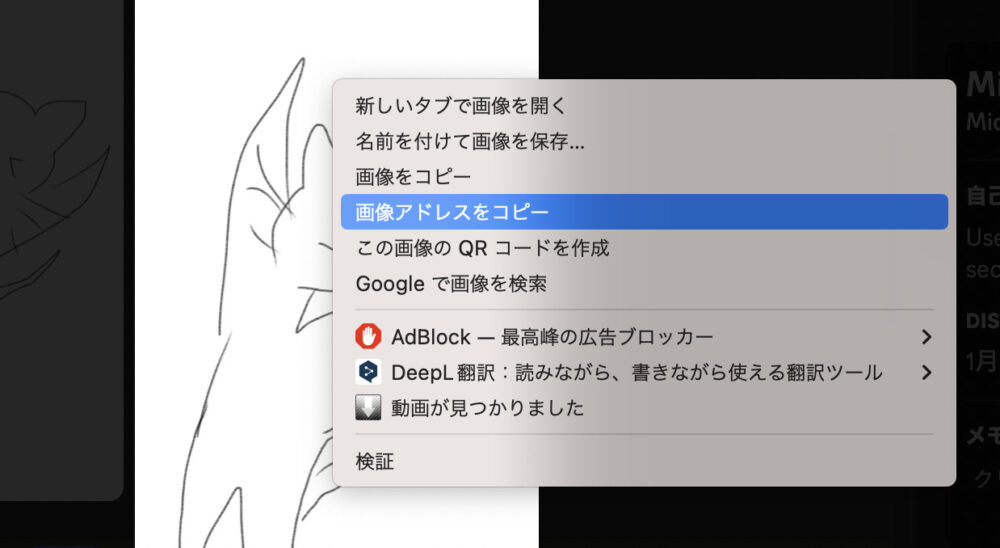
画像をクリックして拡大したのちに、右クリック→「画像アドレスをコピー」を選択します。
これで、この画像のアドレスを取得することが出来ます。
画像を作成していく

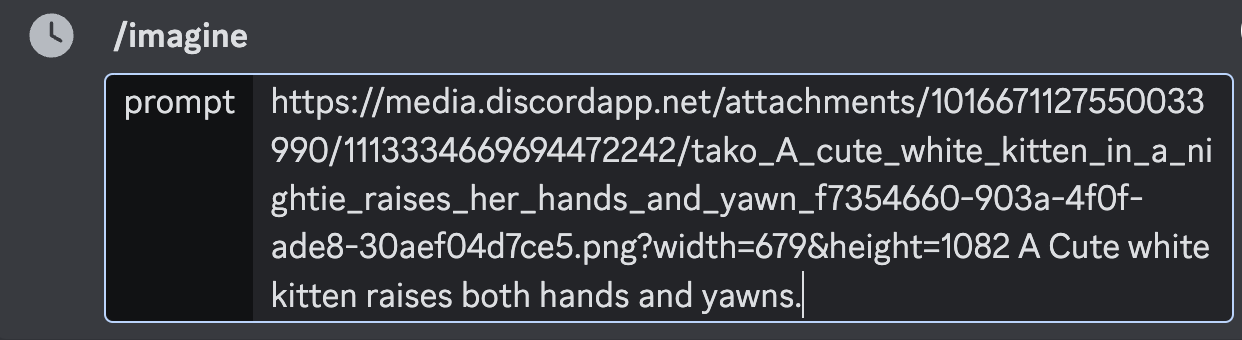
さきほど取得したアドレスをイメージプロンプトにペーストします。
その後に半角を空けて、イメージした絵のプロンプトを入れます。
「可愛い白い子猫が両手を挙げてあくびをしている」という絵を作りたかったので、それをDeepL翻訳で英訳してもらいます。
そうすると、「A Cute white kitten raises both hands and yawns.」と出てきましたので、これをコピー&ペーストします。

上図のようなプロンプトになりました。
これで出力すると以下のような画像になります。

画像の質は低いですが、とりあえず右上の画像をアップスケールしてみます。

さらに、この画像のアドレスを取得します。
そして、さきほどと同じように、画像アドレスをペーストします。続けて、同じテキストプロンプトを入れます。

1回目の生成に比べて質が高い画像ができます。
このように、ミッドジャーニー(Midjourney)で生成する度に元画像がブラッシュアップされていきます。
右下の画像をアップスケールしてみます。

私のイメージと合うイラストが作成されています。
この方法のデメリットは、自分で絵を描く手間があることと、画像アドレスをコピペして画像の質を高める作業が必要になります。
しかし、テキストプロンプトだけで作ったり、ディスクライブするための資料を探したりするよりも、手っ取り早くイメージに合った画像を作れる場合があります。
もし画像生成に行き詰まったら以上のやり方を試すと、案外上手くいくことがあるかもしれません。
作った画像に背景をつける

作成したこの画像に背景をつける方法をご紹介します。
ClipDrop(クリップドロップ)を使う
ClipDrop(クリップドロップ)で、Remove backgroundを行います。
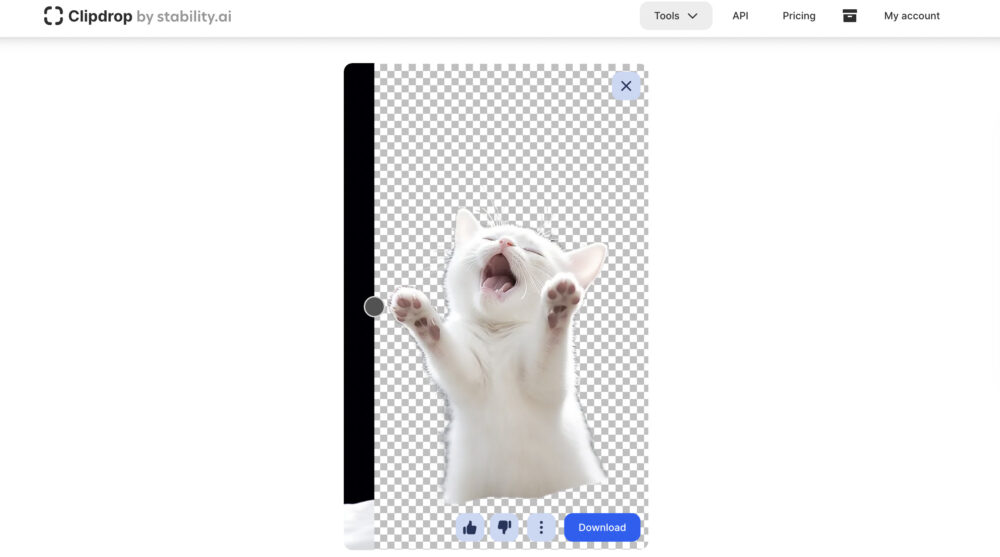
ClipDrop(クリップドロップ)にて、簡単無料で即座に背景を削除することが出来ます。
ClipDrop(クリップドロップ)の詳しい使い方については下の記事をご覧ください。
Canvaを使う

Canvaを使用して、背景画像の上にさきほど切り取った猫の画像を乗せてみました。
合成している部分が不自然ですので、この画像もDiscordに送りましょう。
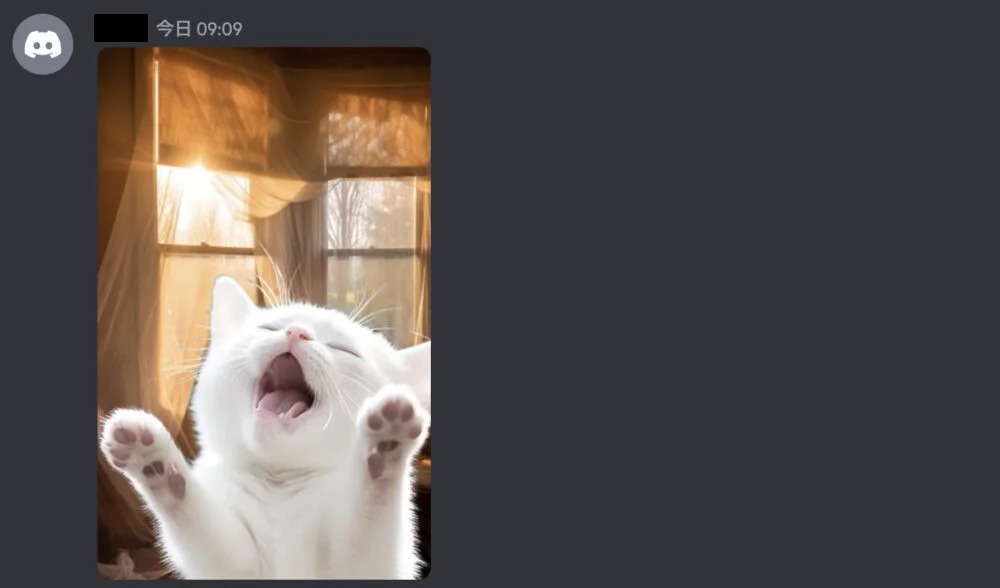
Discordに送りました。
この画像のアドレスをコピーします。
今までの作業と同じように、画像アドレスをペーストして、さらにテキストプロンプトを入れていきます。
テキストプロンプトは、猫に関しては今まで同じ「A Cute white kitten raises both hands and yawns.」です。
背景の画像もミッドジャーニー(Midjourney)で作成していましたので、その時のプロンプトを使用します→「As the sun rises, dazzling light streams into the house through the window」
これらを全て記入します。
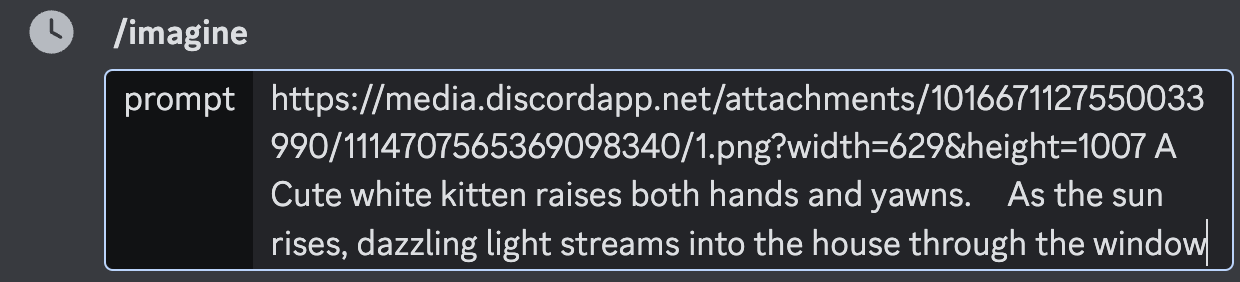
これで画像を生成してみます。

猫と背景が自然な形で表現されています。
右下をアップスケールしてみます。

なかなか良い出来になったと思います。
ブレンド機能も使える
背景を合成したい場合は、ブレンド機能を使用することも有効です。
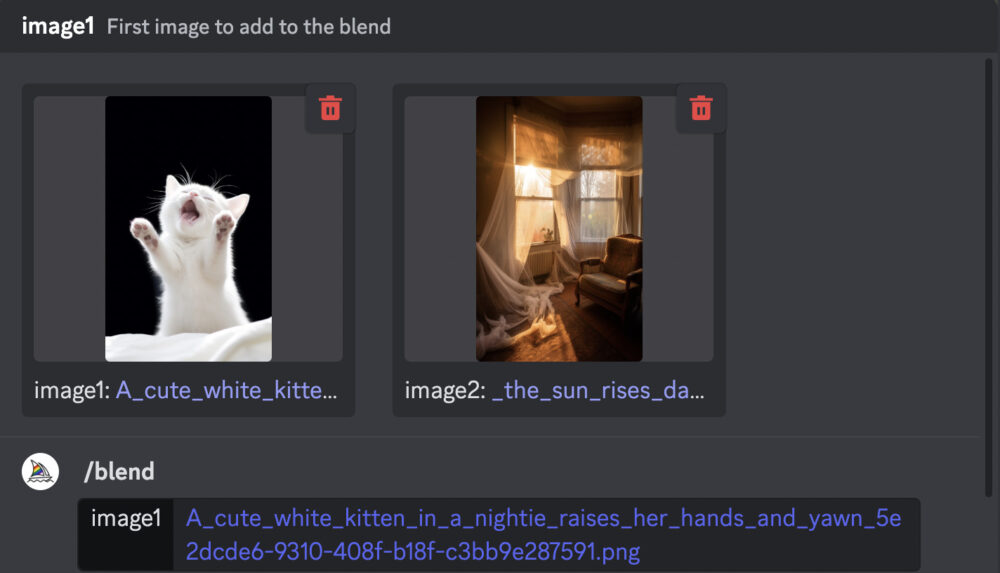
2つの画像を /blend で選択します。

出来た画像が上図になります。
構図としての精度は落ちますが、少ないタスクで背景画像を合成したいときにオススメです。
ブレンド機能の詳しい機能については下の記事をご覧ください。
他のサンプル
以上の方法を他の絵でも試してみます。

上の図は、私がスマホと指を使って描いた画像です。
おばあさんがちょっと考え込んでいる姿を描きたいと思いました。
イメージとしては「優しそうな老婆が物思いにふけっている。青いエプロンをしている。全身。白髪。」というものです。
これをDeepLで英訳します→「A kind-looking old woman is pondering. She is wearing a blue apron. Full body. Gray hair.」

さきほどの画像のアドレス及びプロンプトで作成したのが上図です。
左上の画像をアップスケールします。

ちょっとデフォルメされすぎたので、次の再生成では「real photo」という一文を追記します。

https://s.mj.run/UzKHqQ52h5U A kind-looking old woman is pondering. She is wearing a blue apron. Full body. Gray hair. real photo. --ar 5:8 --style raw
「real photo」を追記することにより、画像のスタイルを修正することができました。
さらに左上の画像をアップスケールします。

上図の画像アドレスをコピー&ペーストして、さきほどと同じプロンプトで再生成します。

このようになりました。
右下の画像をアップスケールします。

これで、私がイメージしていた画像と近いものが無事に出来ました。
背景をClipDrop(クリップドロップ)で切り抜いて、さらにCanvaで猫の画像と合成してみます。
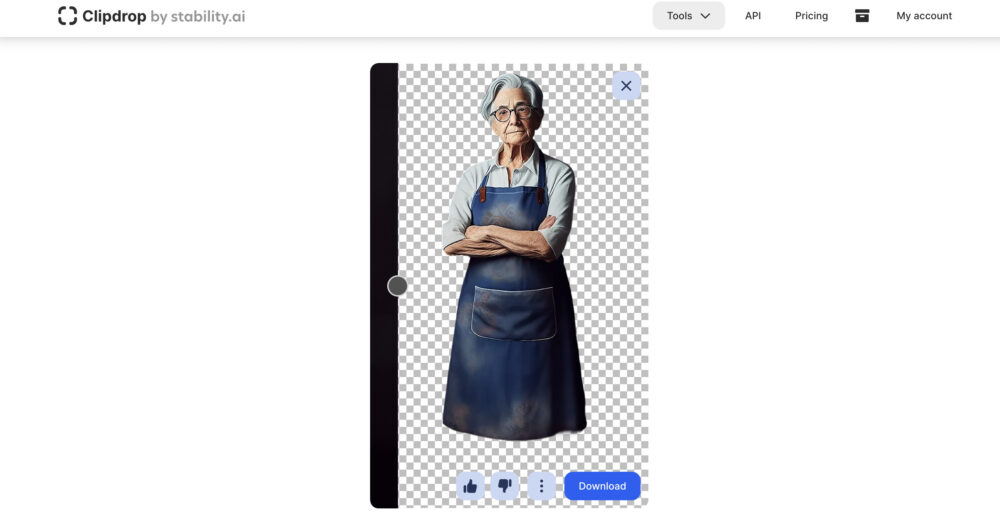
ClipDrop(クリップドロップ)で背景を削除します。

そして、Canvaで作った猫の画像の後ろにおばあさんを入れ込みました。
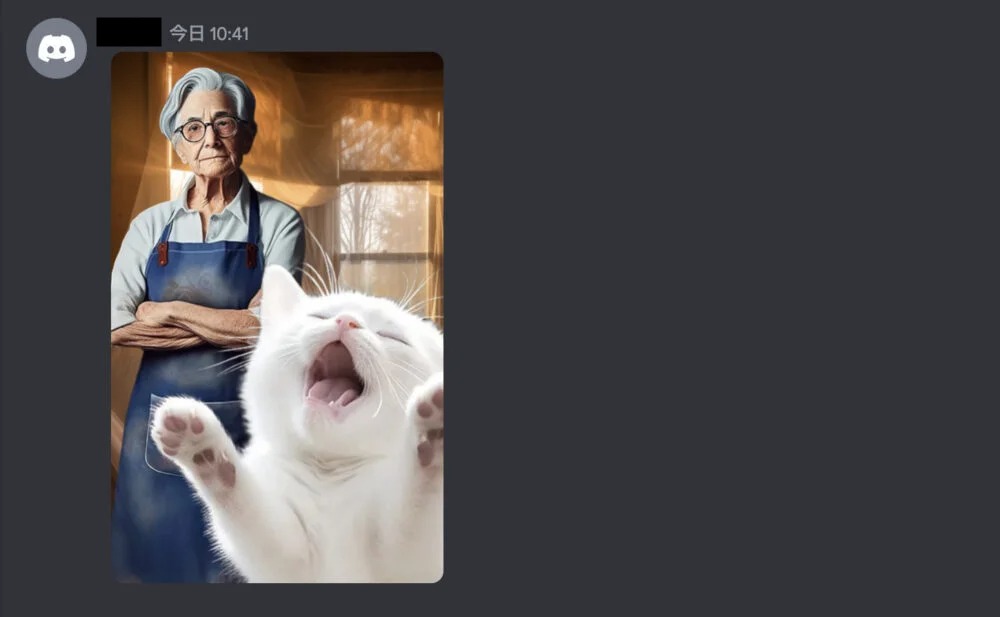
この画像も、再びDiscordに送って、合成の違和感を無くしたいと思ったのですが…。

https://s.mj.run/FvIPBJIxWX0 In a sunlit room, a cat is yawning with both hands raised. Behind it, an old woman folds her arms and looks pensive. --ar 5:9 --style raw --iw 2
お手上げです。
そんなに試してはいないですが、なぜかおばあさんが両手を挙げてしまうことが多いです。
二体以上の人物・動物を細かく指示通りに動かすのは、現在のところ難しい気がします(マルチプロンプトやブレンド機能、ディスクライブ機能を使用しても困難でした)。
ということで、まだまだ欠点はありますが、簡単なイメージであれば手書きからブラッシュアップしていく方が効率的な場合があるということでした。


