ロゴ.png)


ステイブル・ディフュージョン(Stable Diffusion)を導入する知識がなくても、誰でもすぐにAIで画像生成を始められるSeaArtというサイトのご紹介です。
PC(Macも)やスマホでも普通に使用可能です。
SeaArtでは、無料で毎日80枚まで画像生成することが出来ます(2023年6月19日時点)。
SeaArtにはステイブル・ディフュージョン(Stable Diffusion)の主要な機能が揃っています。
注意点としては、意図せずにアダルトな画像を生成したり、閲覧してしまう可能性があることです。ご理解の上でお使いください。
以下でSeaArtについて詳しく解説していきます。
- 1 SeaArtに行く
- 2 ログイン方法
- 3 課金について
- 4 画像を生成する
- 5 img2imgについて(バリエーション)
- 6 プロンプトについて
- 7 基本設定について
- 8 ランダム生成を楽しむ
- 9 他人の画像で「創作」する
- 10 画像を保存する方法
- 11 モードについて
- 12 モデルについて
- 13 モデルの人気ランキング
- 14 他のおすすめモデル
- 15 LoRAについて
- 16 高級設定について
- 17 コントロールネットについて
- 18 Expansionについて
- 19 アップスケールについて
- 20 画像情報について
- 21 Previewについて
- 22 Prompt Studioについて
- 23 NSFWについて
- 24 商用利用について
- 25 まとめ

SeaArtに行く
まずは、SeaArtのサイトに行きましょう。
こちらのリンクから飛ぶことが出来ます→https://www.seaart.ai/
上図がSeaArtのHOME画面になります。
SeaArtで作成した誰かの画像がずらっと並んでいます。
![]()
![]()
画面上部のタブから、ジャンルごとに画像を閲覧することが可能です。
上図は風景タブの画像一覧です。

こちらは動物タブの画像一覧です。
上図は油絵タブの画像一覧です。
このように、様々なジャンルの画像をSeaArtでは作り出すことが可能です。
上図の画像をひとつ選んでクリックしてみます。
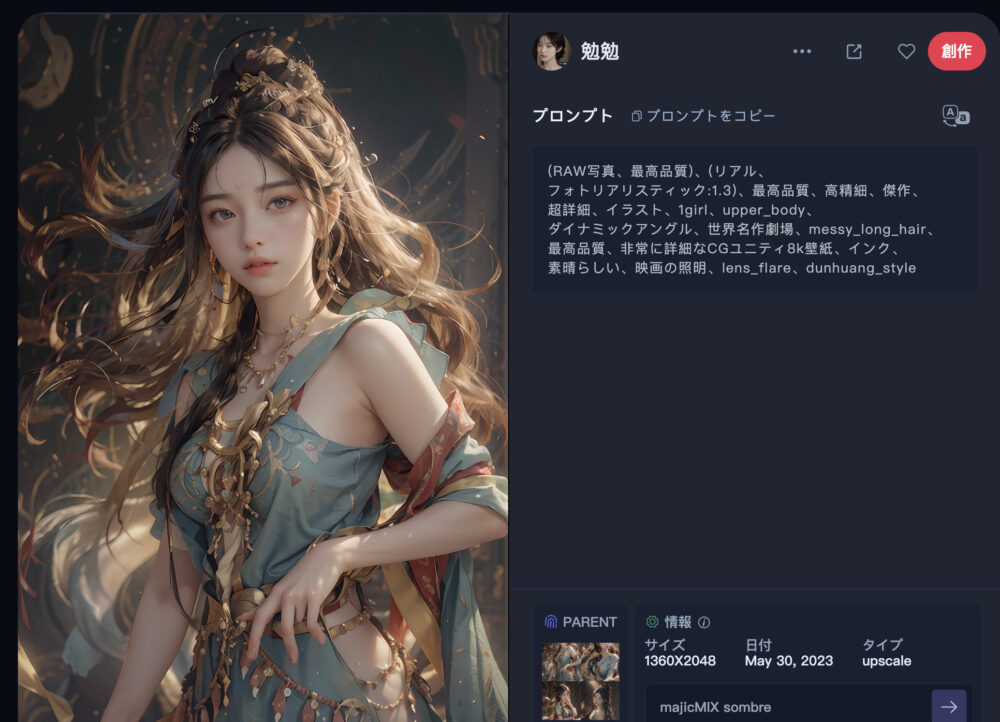
クリックすると、画像がアップになり、詳細な情報が開示されます。
プロンプトも表示されます。
そのプロンプトをコピーしたり、右上の「創作」ボタンを押して同じような作品を作ることが出来ます。
ただし、画像を生成するにはログインをする必要があります。
ログインの手順は至ってシンプルです。

ログイン方法

HOME画面右上の「ログイン」ボタンを押すとログインすることが出来ます。
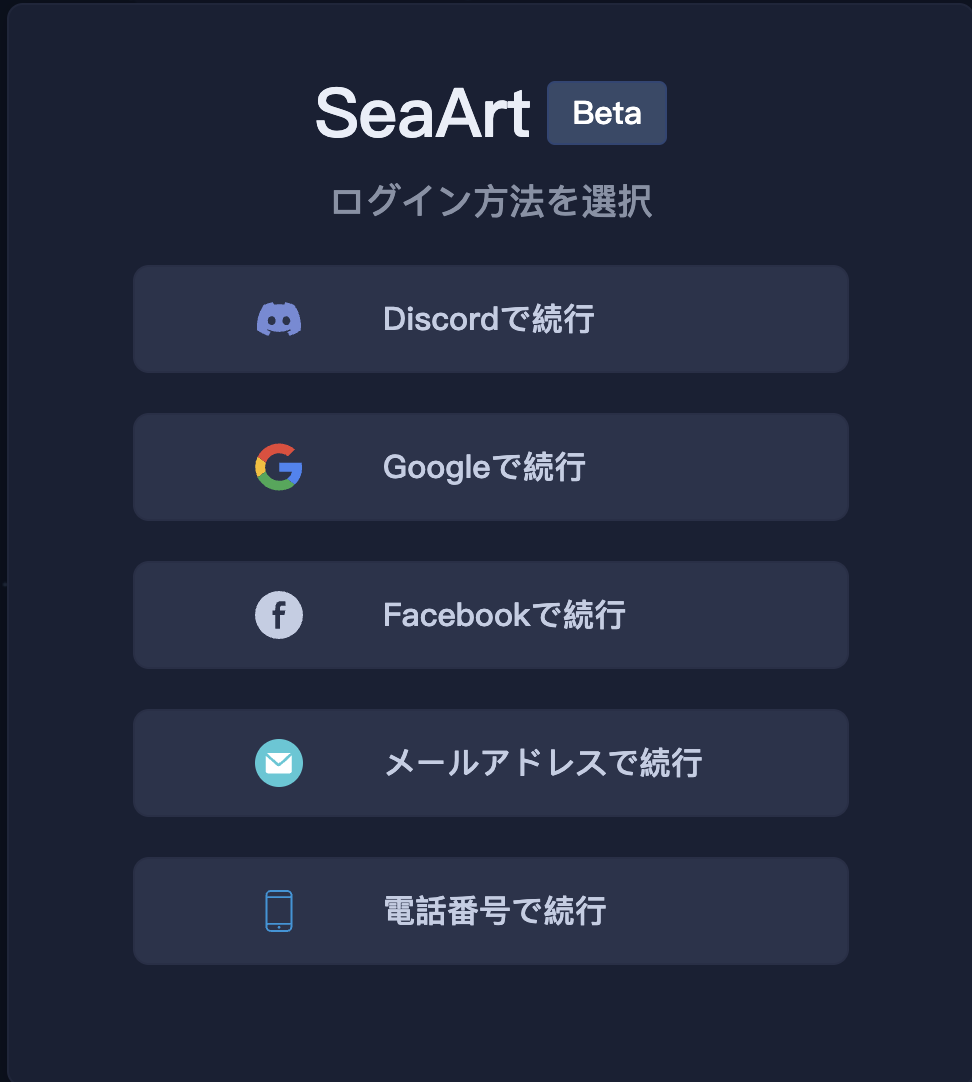
ログイン方法は上記5種類から選ぶことが出来ます。
私はGoogleアカウントでログインしてみます。

Googleアカウントを選択すると、上図の表示になります。
下記の順に実施していきます。
- 自由にニックネームを入力し、好みのジャンルを選択します。
- 「私は18歳以上です」のスイッチをオンにします。
- 画面最下部の「使用を開始する」を押します。
以上を実行すると、画面右上のアイコンが自身のアカウントのものに変わっていると思います。
これで、ログイン完了となります。
ログイン完了後は、ほぼ全ての機能を無料で使用することが出来ます(2023年6月19日時点)。
課金について
SeaArtでは、2023年6月19日時点では課金する方法がありません。
課金しなくてもほぼ全ての機能が使用可能となっています。
将来的には課金することもできるようになると思います。
毎日80枚まで無料で生成可能

現在は期間限定で無料で画像生成可能となっています。
ただし画像生成回数には制限があり、1日80枚が限度です。それを超えるとコインを消費していきます。
次の日には再び無料で80枚の画像生成が出来るようになります。
※SeaArtのユーザー数増加のため、2023年6月6日のアップデートにて、毎日の無料画像生成枚数100枚→80枚へと減少しています。
タスク(ログインボーナスなど)
画面右上の四つの四角形マークを押して、「タスク」を選択します。
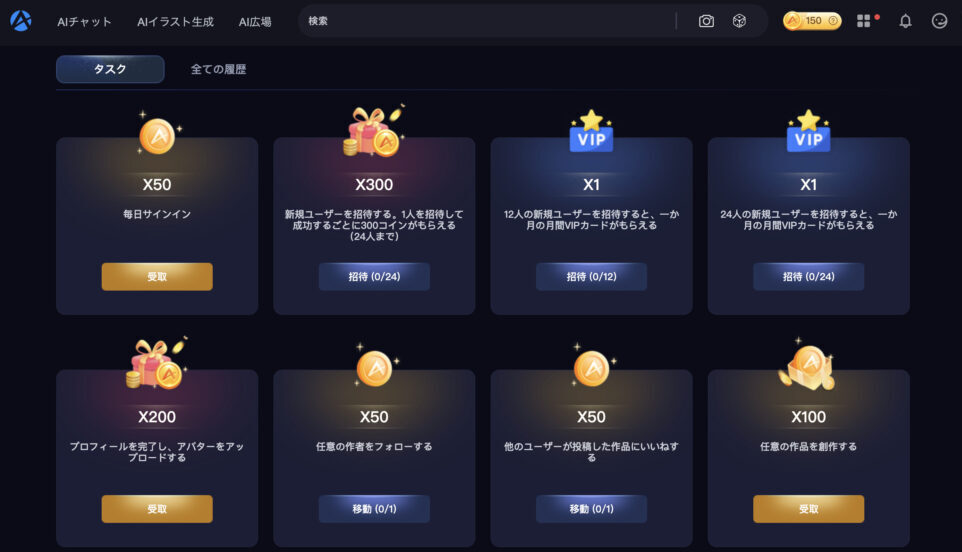
そうすると上図のように、ログインボーナスなどの報酬を受け取ることが出来る画面が表示されます。
毎日ログインすると50コインをもらうことが出来ます。
1コインで1枚画像を生成することが出来ます。

ログインボーナスなどを受け取ると、所持コインに加算されていきます(多少タイムラグがあります)。
招待について
SeaArtに誰かを招待することが出来れば特典が付与されます。

タスクの上図の「招待」ボタンをクリックします。

そうすると、「招待リンクがコピーされました」と表示されます。
https://www.seaart.ai/s/UlR3Hw
コピーされた内容は上記のようなものです。
これを招待する相手のメールなどに送ります。

送られたメールのリンクを踏んで、その相手がSeaArtにログイン出来れば招待が成功します。
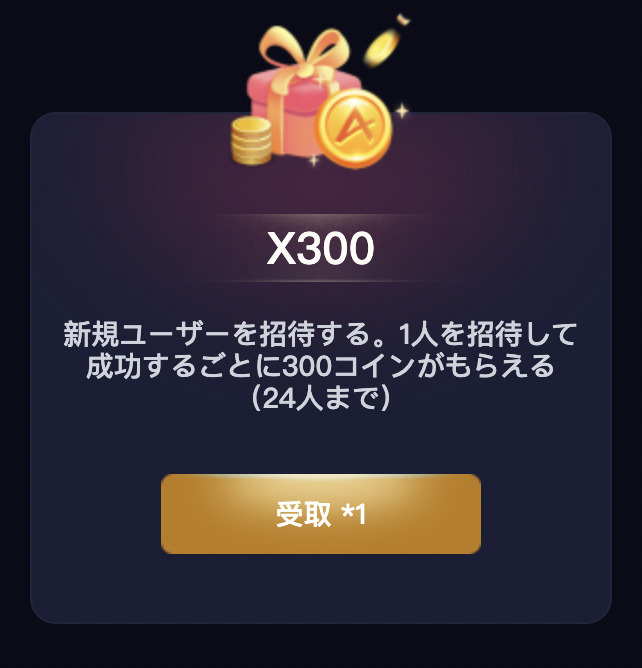
招待に成功すると、タスクでボーナスを受け取ることが出来ます。
ひとり招待するごとに毎回300コインをもらえます(最大24人まで)。
生成した画像を隠す方法

誰かひとりを招待すると、上図のように「Invite 1 new person to unlock the rights of hidden/public works=1人新たに招待すると、隠し作品・公開作品の権利を解除する」という機能が開放されます。
これは、自身が作成した画像を他の人が閲覧できないようにする機能だと思います。

右上のアイコンの「設定」をクリックします。

「個人設定」の右にある「創作設定」をクリックします。
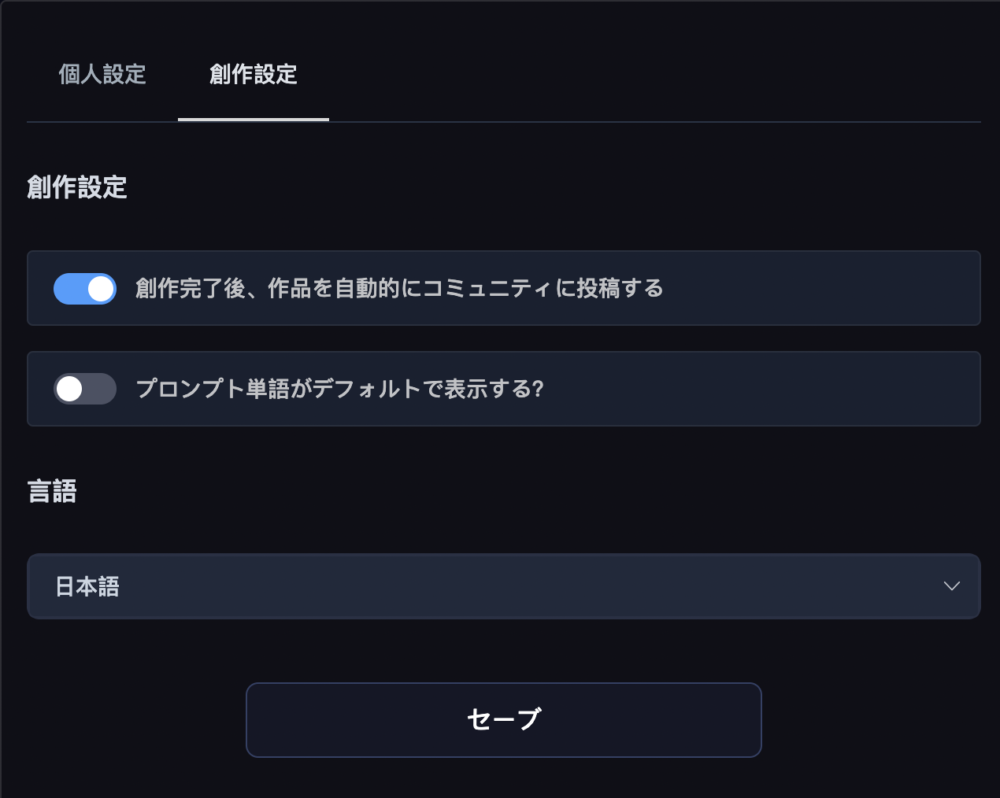
「創作完了後、作品を自動的にコミュニティに投稿する」のスイッチがオンになっています。

これをオフにすることが出来ます。
こうすることで、画像を生成しても世間に見られないようになると考えられます。
ひとり招待するだけで300コインと、この機能が開放されますので、招待してみる価値はあるかもしれません。
画像を生成する
SeaArtでAI画像を生成する方法をご紹介します。

HOME画面最上部の左側に「AIイラスト作成」という文字が見えます。
それをクリックしましょう。
そうすると上図のような画面になります。
左サイドバーが「Generate」になっていることを確認してください。
この画面で画像を作成していくことが出来ます。

画面最下部のメッセージ欄に、私のアイコン画像でもある「クラゲ帽子を被った少年」と記入してエンターキーを押します。
SeaArtでは日本語にも対応しています。

1分〜数分で画像が生成されます。
5つの画像が横並びに表示されます。
諸機能について
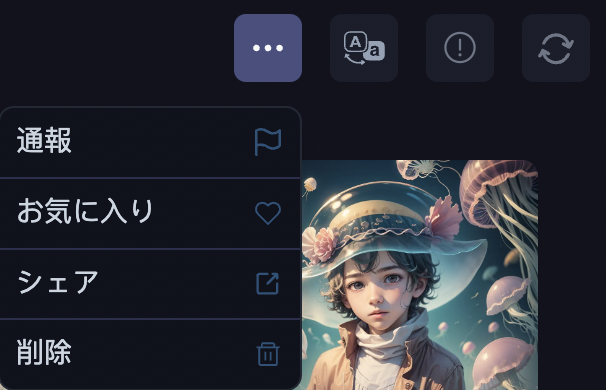
画像が並んでいる上に「…」マークがあります。
それをクリックすると、
- 通報
- お気に入り
- シェア
- 削除
の項目が表示されます。
画像をお気に入り登録して、マイページでいつでも閲覧したり、シェア(画像リンクをコピーすること)したり、画像を削除することが出来ます。
本来のプロンプトを表示する

画像一覧の上に「Aa」マークがあります。
日本語で書かれたプロンプトは、実際には英訳されて画像生成に使われます。
その実際の英語のプロンプトを「Aa」マークを押すと確認することが出来ます。
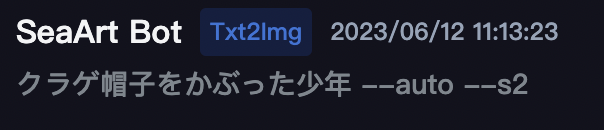
このように「クラゲ帽子をかぶった少年」と日本語で入力して作成しましたが、
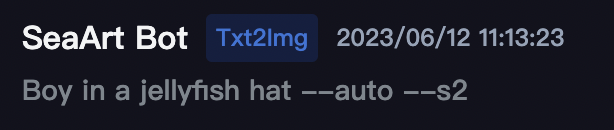
「Aa」マークを押すと上図のように「Boy in a jellyfish hat」と表示されます。
この英語のプロンプトが実際には使用されています。
情報を見る

画像一覧の上に「!」マークがあります。
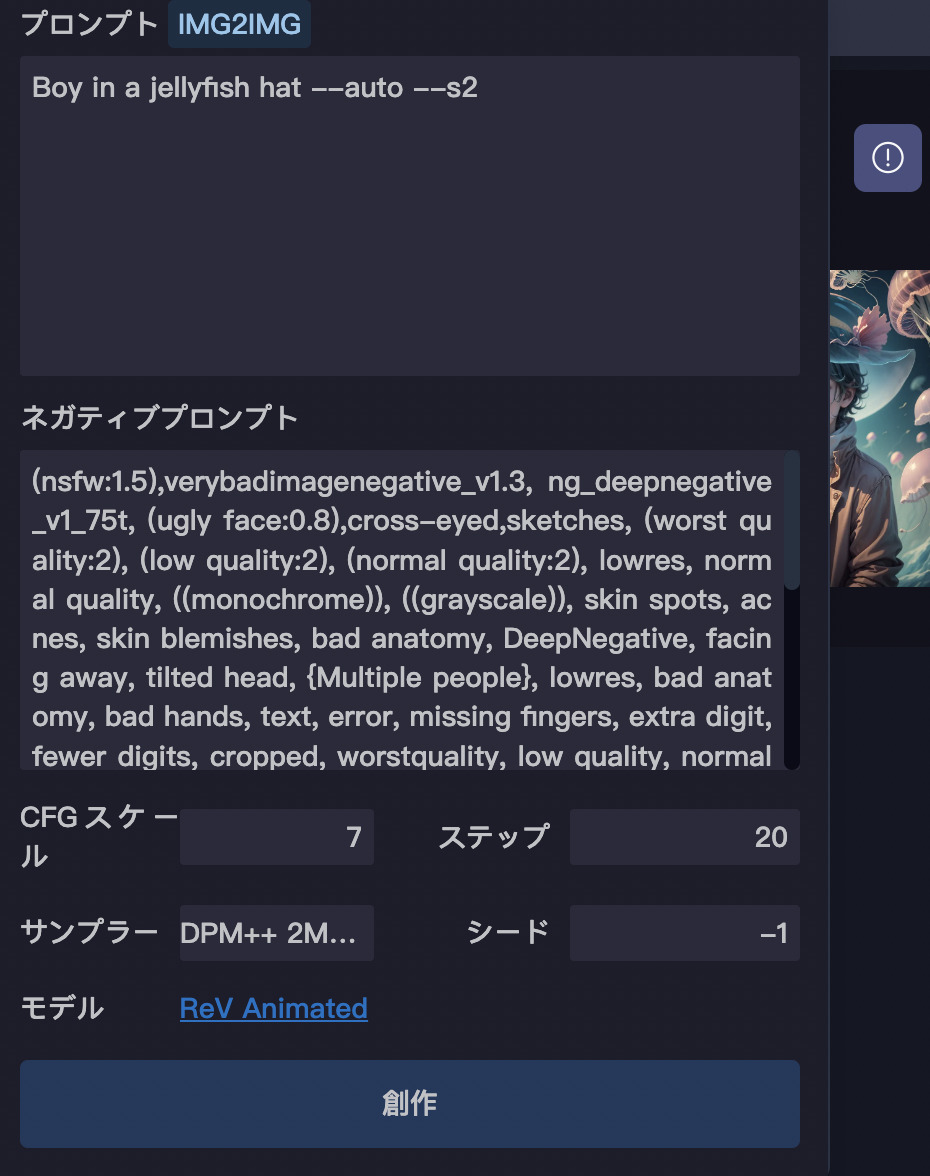
それを押すと、その画像の詳細な情報を確認することが出来ます。
リロール

画像一覧の上にある「丸矢印」マークを押すと、その画像を作成したのと同じプロンプトと同じパラメーターを再現してくれます。
コントロールネットでの画像生成後にこのマークを押すと、コントロールネットに遷移して、同じ条件を設定してくるので便利です。
一番左の画像について
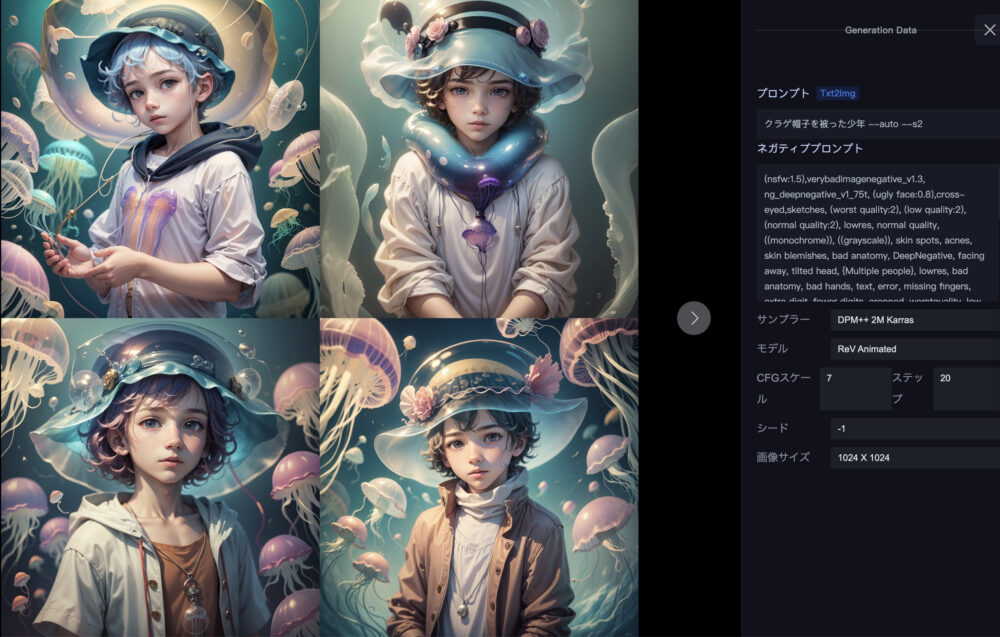
一番左の、画像が4つ並んだものをクリックしました。
これは、今回生成された画像を4つ並べてくれています。
右側には詳細な情報が記載されています。
個別画像について

それ以外の各画像をクリックすると、
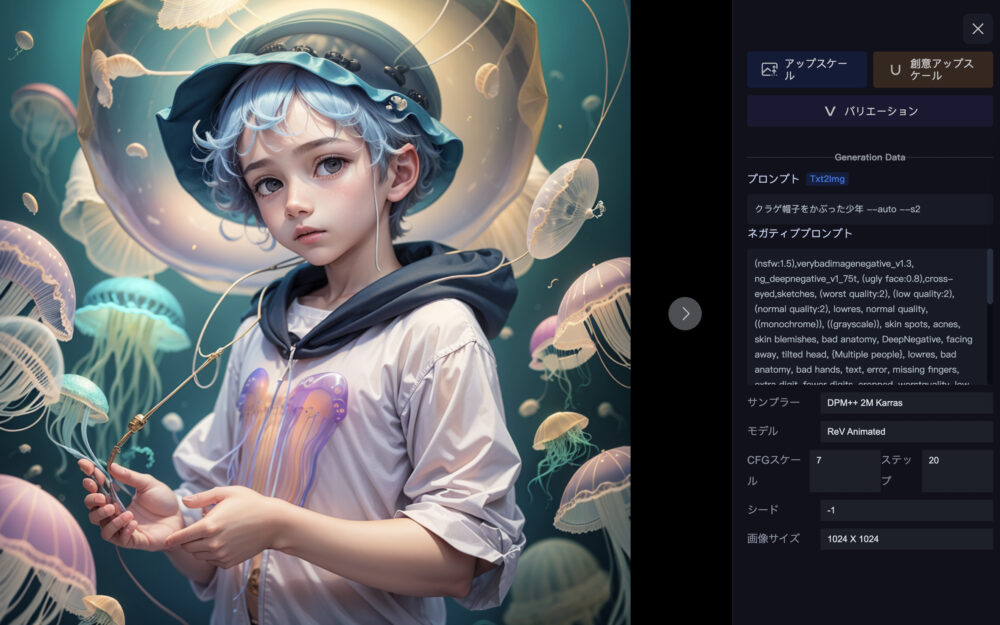
上図のような画面になります。

画面右上に、下記の3項目が確認できます。
- アップスケール
- 創意アップスケール
- バリエーション
以下で解説していきます。
アップスケールについて
「アップスケール」をクリックします。
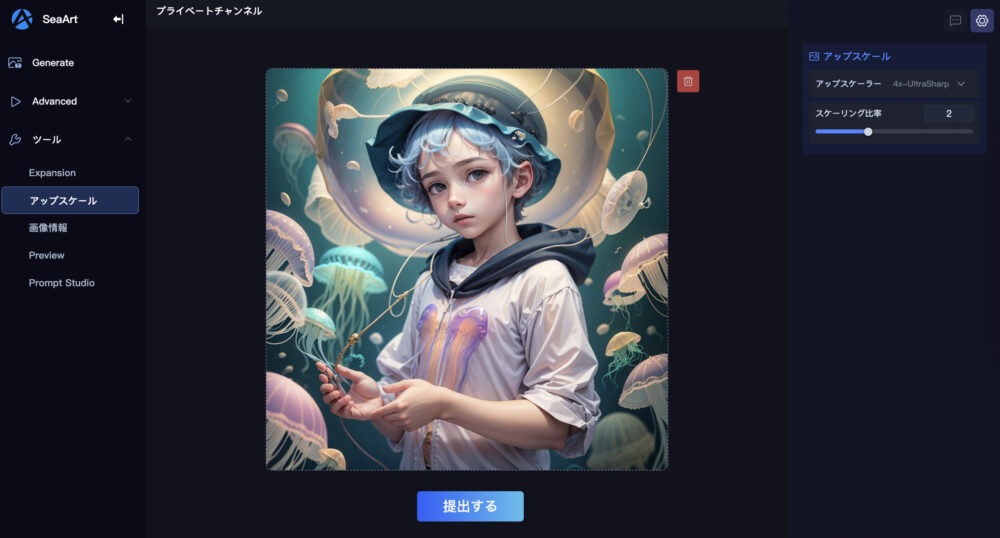
すると、上図の表示になります。
左サイドバーを見ると「アップスケール」が選択されていることが分かります。

この画面でアップスケールを行うことが出来ます。
アップスケールを実行すると、高解像度の画像を出力できます(アップスケーラーなどについては後述します)。
画面下部の「提出する」を押すと、アップスケールが開始されます。
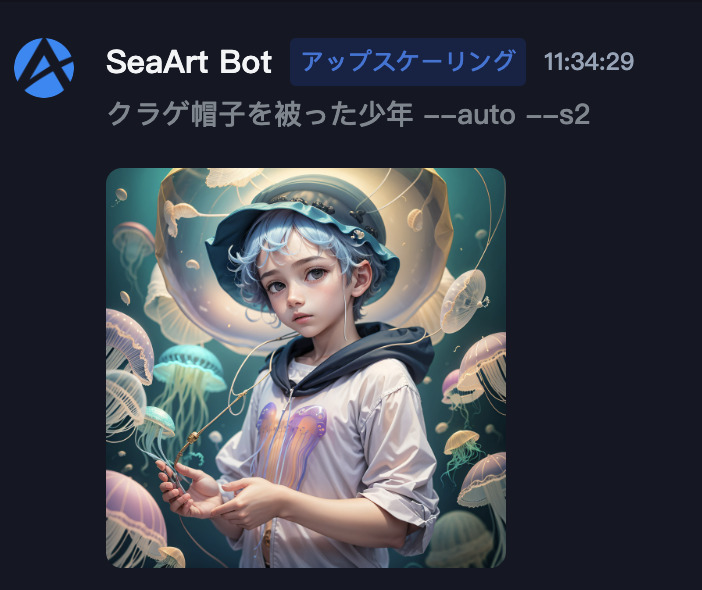
画像がアップスケールされました。
解像度は「1024×1024」→「2048×2048」に変更されています。
画像をクリックします。

アップスケールされた画像は、画面下の虫眼鏡でアップにしても緻密に描かれていることがわかります。

画面下の円形の左右の矢印を押すと、それぞれ画像を90度ずつ左右に回転することが出来ます。
創意アップスケールについて
「創意アップスケール」をクリックすると、即座にアップスケールが開始されます。
「創意アップスケール」は、よりクリエイティブな効果を生み出すことが可能です。
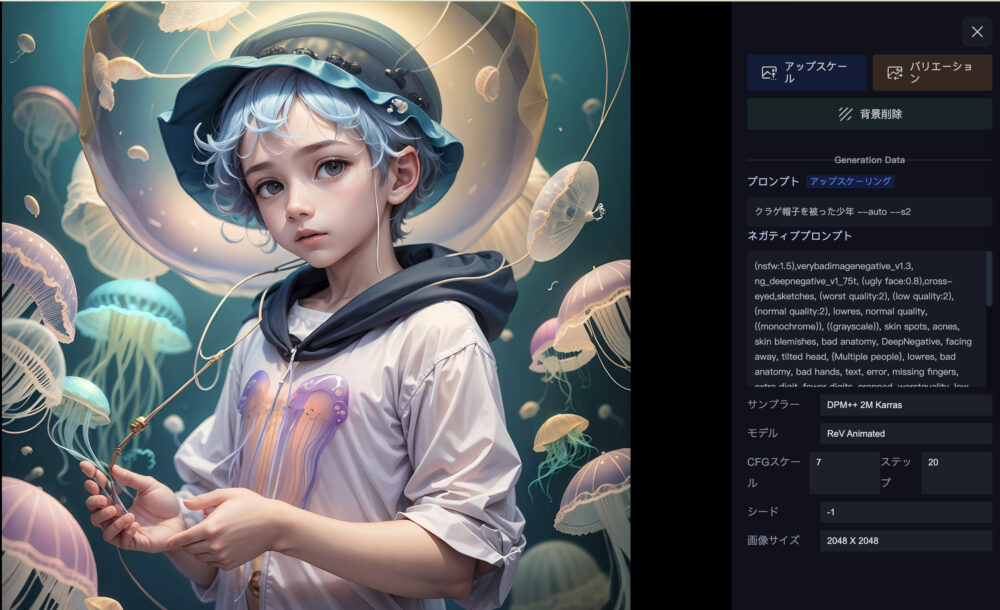
上図は、「創意アップスケール」で作成された画像です。
画像サイズは「1024×1024」→「2048×2048」にアップスケールされています。

さらに、「創意アップスケール」で作成された画像に関しては、画面右上にて、以下の3つの機能を使用することが出来ます。
- アップスケール
- バリエーション
- 背景削除
「創意アップスケール」で作られた画像は、これらの機能が使えます。
アップスケール
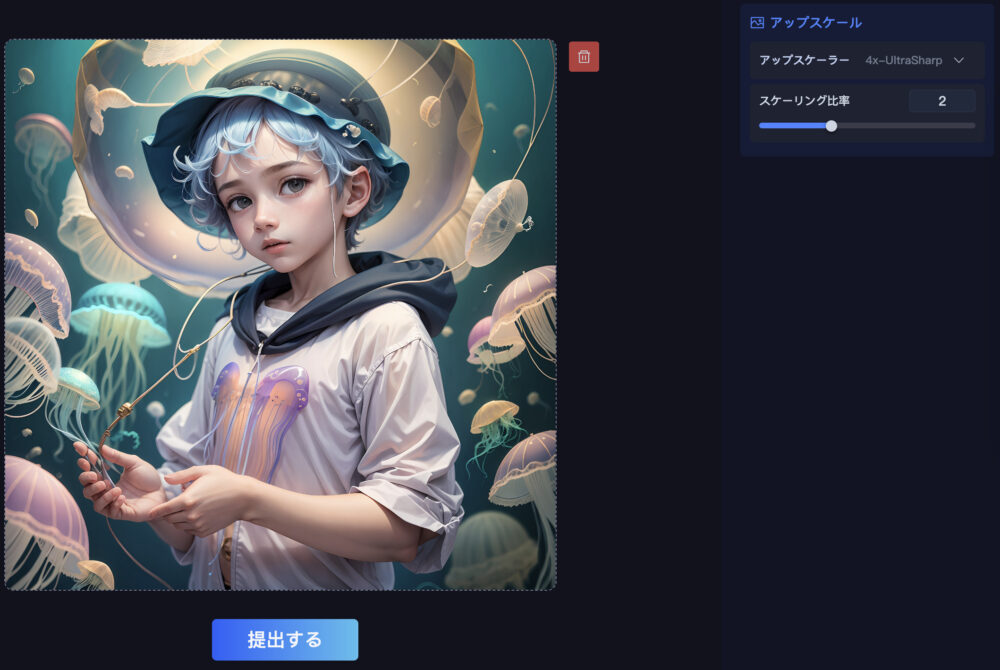
「アップスケール」を押すと、アップスケール画面に遷移します。
ただし、この時点ですでに解像度が上がっていますので、「提出する」をクリックするとさらに画像サイズが上昇します。
大きな画像サイズになりすぎることに注意してください。
バリエーション
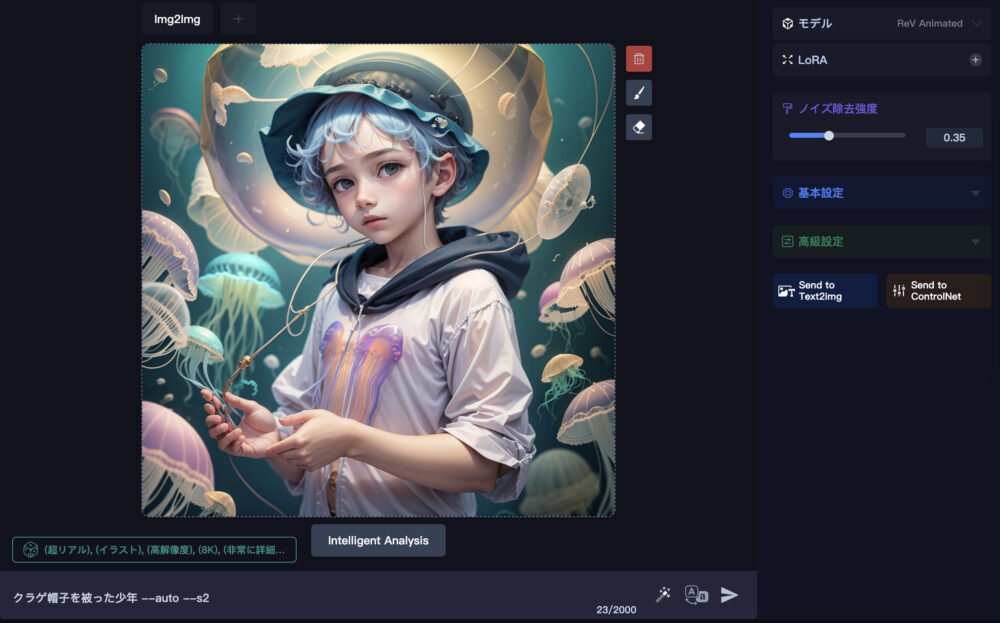
バリエーションボタンを押すと、上図のような画面になります。
この機能についてはすぐ後に解説します。
背景削除

背景削除ボタンを押すと、文字通り背景が削除されます。
しかし、帽子や衣服の一部も背景として切り取られてしまいました。

上の画像はClipDrop(クリップドロップ)を使用して、背景を削除しました。
ClipDrop(クリップドロップ)の場合は背景がうっすら残ってしまっていますが、衣服は無事です。
背景削除サイトも色々ありますので、使い分けて利用すると良いかもしれません。
ClipDrop(クリップドロップ)についての詳細は以下からご覧ください。
※「創意アップスケール」と普通のアップスケールの画質の違いについては後述します。
img2imgについて(バリエーション)

画像生成画面(Generate)の画像をクリックします。
画面右上に「バリエーション」の項目がありますので、クリックします。
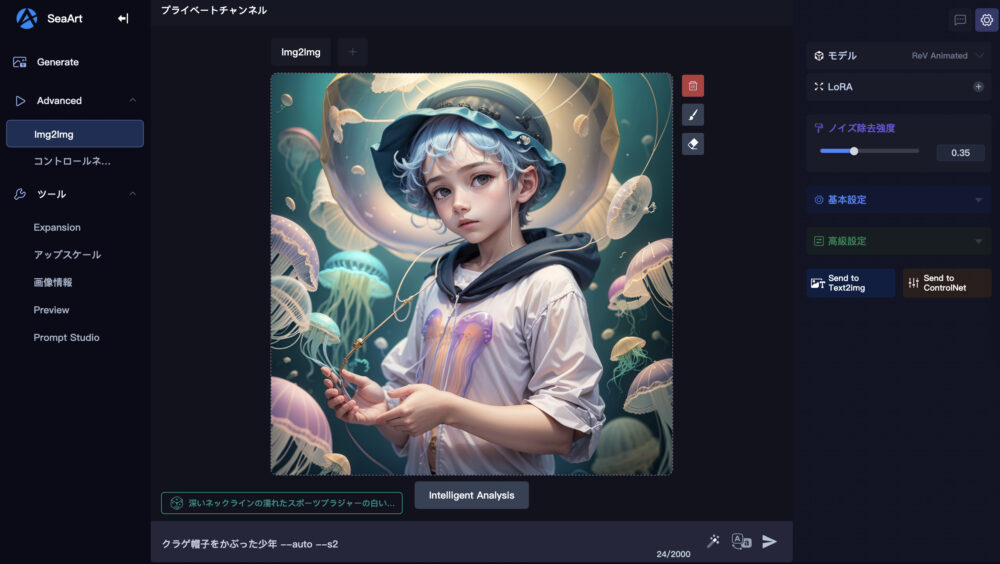
そうすると、上図へと画面が遷移します。

左のサイドバーには「img2img」が選択されていることが確認できます。
つまり、「バリエーション」を押すことで、「img2img」モードへと移行したことが分かります。
img2imgとは?
「img2img」とは、「Image-to-Image」の略称です。
Imageというのは画像のことです。
「Image-to-Image」は、画像から画像を生成する、という意味があります。
基本的には、「img2img」では、画像だけではなく、テキストプロンプトも用いて、画像を生成することになります。
そうすることで、元の画像を踏襲しつつも、テキストプロンプトの指示も反映した画像を生成することが出来ます。
無調整で img2img を実行
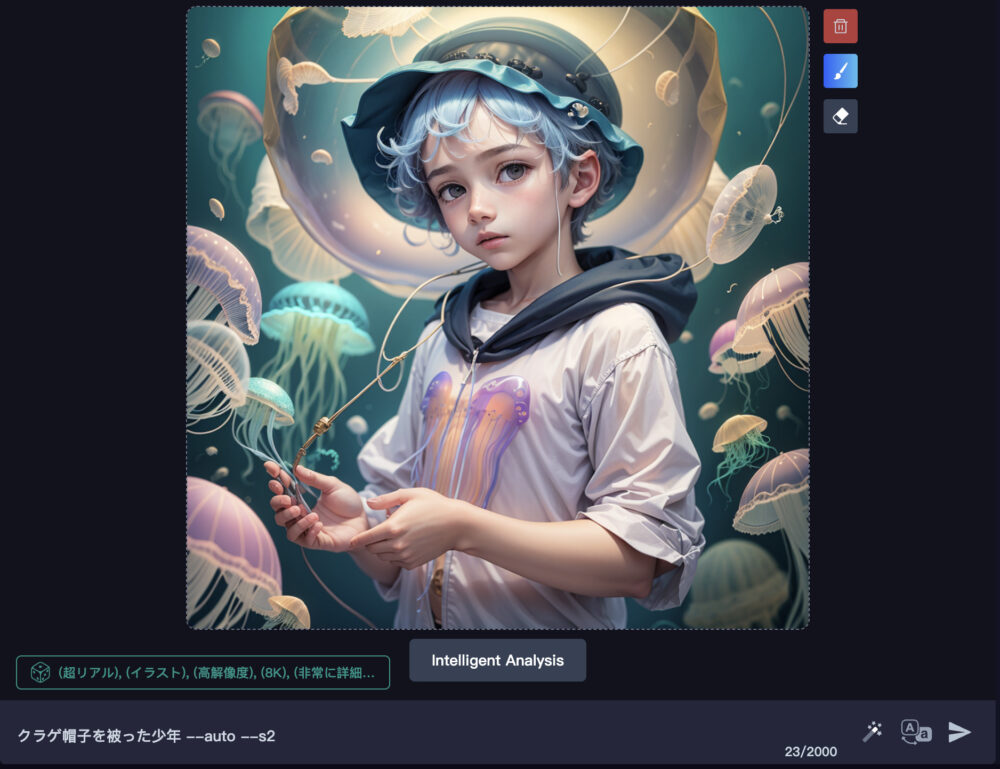
この画像を特に何の設定も変えずに、紙飛行機ボタン(もしくはメッセージ欄でエンターキー)を押してみます。

出来た画像は上のようになります。
元画像とほとんど変わっていませんし、4枚の画像もそれぞれほぼ変化がありません。
ノイズ除去強度について
さきほどの img2img では、画像に変化が起きませんでしたが、これはノイズ除去強度が大きく影響しています。
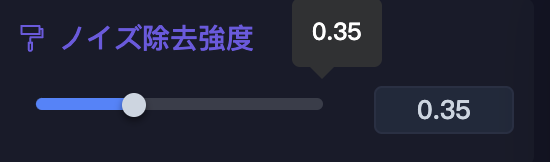
画面右上に「ノイズ除去強度」の項目があります。
デフォルトは「0.35」となっています。
- 「ノイズ除去強度」が低いほどバリエーションの変化が少なく、元の画像を忠実に再現します。
- 「ノイズ除去強度」が高いほどバリエーションの変化が大きく、元の画像からかけ離れていきます。
「ノイズ除去強度」の範囲は「0〜1」を取ります。
デフォルトの「0.35」はノイズ除去強度が低いため、img2img を行っても画像に変化が起きませんでした。
これを試しに最高の「1」にまで上げて、img2img を実行してみます。

出来た画像がこれになります。
「ノイズ除去強度」を1に上げるだけで、他は何も調整していません。
各画像のポーズも違いますし、登場人物が増えていたりもします。
かなりバリエーションの幅が増えたことが分かります。
プロンプトを変える
再び元の画像に戻って、img2img を行います。
画面最下部のメッセージ欄のプロンプトを変更します。

「クラゲ帽子を被った少年」に「炎に包まれる」というテキストを追記しました。
さらに、ノイズ除去強度を1に上げてimg2img を実行します。

そうすると、上図のように、元画像をイメージしながらも、炎の要素が加わった画像が生成されます。
Intelligent Analysisを使う
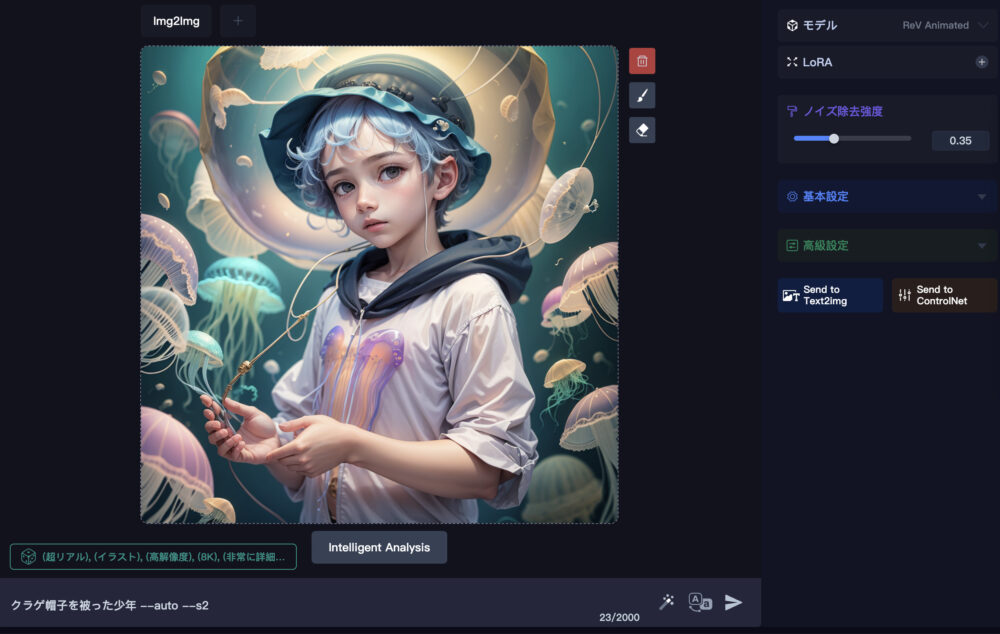

img2imgの画面下部中央に「Intelligent Analysis」というボタンがあります。
それを押すことで、AIが画像を分析してその画像に適したプロンプトに書き換えてくれます。

「Intelligent Analysis」を実行すると、上図のように書き換えられました(この機能はimg2img画面で新たに画像をアップロードした時にも自動的に発動します)。
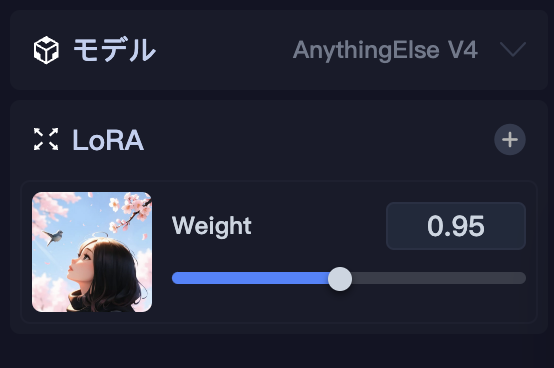
また、右上のモデルも自動的に変更されています。
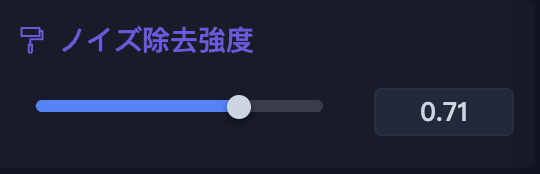
「ノイズ除去強度」はデフォルトの値(0.35)のままですので、0.71程度まで上げて生成してみます。

そうすることで、大幅に元画像が変更されました。
このように、img2img ではプロンプトを変更することで、元画像に対して変化を加えることが出来ます(ノイズ除去強度を高く設定する必要あり)。
インペインティングについて
再び元の画像に戻ります。
この画像の右手の指が7、8本あるのが気になりました。
バリエーションでは、指の部分だけを指定して描き変えることが出来ます。

画面右上の筆のマークを押します。

そして、右手の部分を塗っていきます。
白く塗られたところのみが、再生成される箇所です。

プロンプトも指定します。
白く塗った部分にのみ対応するプロンプトを記入します。
今回は、「拳を握る 背景」と入れます。

それで出来た画像が上図になります。
指の修正は部分的な再生成でも難しい場合がありますが、元画像よりは自然な形になっています。
以上のように、バリエーションでは、出来た画像に対して様々な修正や変化を加えることが出来ます。
※モデルやシードなどについては後に詳しく解説します。
プロンプトについて
SeaArtのプロンプトのコツやルールについて解説します。
「最高品質」「傑作」を冒頭に置く

プロンプトの冒頭に「傑作」「最高品質」を入れておくと、品質が大幅に向上するとされています。

上の画像は、「傑作、最高品質、クラゲ帽子を被った少年」で作成したものです。
冒頭に「傑作」「最高品質」を入れておくと完成度が高くなりますが、抽象的になる可能性もあります。
前にあるプロンプトが優先されやすい
基本的にはメッセージ欄の前方にあるプロンプトほど、画像生成に影響を及びし易いとされています。
最も強調したいプロンプトは前方へ配置すると良いでしょう。
プロンプトは「、」で区切る
プロンプトとプロンプトの間は「、」で区切ると安定します。

「りんご、ぶどう」のように「、」で区切ります。
「Aa」を押して、実際の英語で書かれたプロンプトを確認してみます。

上図のように、「Apples, grapes」となっています。
「、」は半角カンマに変換され、さらにその直後に「半角スペース」が自動的に挿入されている形になります。
半角カンマと半角スペースは、ステイブル・ディフュージョン(Stable Diffusion)でプロンプト同士を区切る方法とされています。
「、」を入れるだけで自動的に正しい区切り方をSeaArtではやってくれます。
強調構文について
プロンプトには強調構文というものがあります(重み付け、ウェイトなどとも言います)。
あるプロンプトを画像に強く影響を与えたい時や、逆に弱めたい場合に使用します。
(プロンプト)を使う
プロンプトを()で囲むと、そのプロンプトは 1.1 倍強化されます。
例えば、「りんご ぶどう」というプロンプトがあった場合、「りんご (ぶどう)」にすると、ぶどうが強調されて表現されやすいです。
()は重複させることもできます。
((ぶどう))とした場合、1.1×1.1で1.21倍の強調効果となります。
(((ぶどう)))ならば1.1×1.1×1.1=1.33倍の強調効果となります。

プロンプト「りんご、ぶどう」
強調構文を用いずに、「りんご、ぶどう」で作成しました。
りんごとぶどうが同じぐらいの露出になっています。

プロンプト「りんご、(((ぶどう)))」
(((ぶどう)))で、ぶどうを約1.3倍強調しました。
ぶどうの露出がりんごを圧倒しています。
{プロンプト}を使う
また、プロンプトを{}で囲むと、そのプロンプトは1.05倍強化されます。
こちらも、{{{ぶどう}}}などのように重複させると、1.05×1.05×1.05=1.15倍という風に重複効果があります。
[プロンプト]を使う
一方で、プロンプトを[] で囲むと1.1倍の弱体化が生じます。
プロンプトの要素を弱めたい場合に、[]を使用します。
こちらも他の強調構文と同様に、[[[ぶどう]]]などのように重複させると、重複効果が反映されます。

プロンプト「りんご、[ぶどう]」
[ぶどう]で、ぶどうを弱体化させています。りんごの露出が増えています。
弱めるのではなく、指定したプロンプトの要素を除外したい場合はネガティブプロンプトを使用すると効果的です。
ネガティブプロンプトについては後述します。
(プロンプト:数字)を使う
プロンプトを()で囲み、さらに「:」を置いてその直後に数字を記入します。
そうすることで、その数字の値の分だけ強調されます。
例えば、「りんご、(ぶどう1.1)」というプロンプトの場合は、ぶどうは1.1倍強調されます。
「りんご、(ぶどう1.3)」であれば、ぶどうが1.3倍強調されます。
「りんご、(ぶどう0.9)」であれば、ぶどうが1.1倍弱体化されます。
マジックワンドを使う
SeaArtにはマジックワンドという機能があります。

メッセージ欄の右側にある杖のマークを押すと、入力しているプロンプトの質を高めてくれます。

上図の「遠くからカラスがやってくる」というプロンプトに対して、杖のマークを押してみます。

そうすると、上図のようにAIが勝手にプロンプトの質を高めてくれます。

プロンプト「遠くからカラスがやってくる --auto --s2」
上図はマジックワンドを使用する前のプロンプトで出来た画像です。

プロンプト「(masterpiece)、(best quality)、(extremely detailed)、(ultra-detailed)の(CG unity 8k wallpaper)の中に、枝に止まった(crow)が映り込んでいる。雰囲気は(quiet)で、(twilight)と(serene) 。白い雲が描かれており、背景は淡いグラデーションを用いた(watercolor)のようなもの。 --auto --s2」
上図はマジックワンドを使用したプロンプトで作った画像です。
マジックワンドを使用すると画像の質は上がりますが、カラスの要素は薄まっています。
マジックワンドのプロンプトは、元のプロンプトの意味合いから遠ざかる可能性があります。
基本設定について
アスペクト比を変更する
SeaArtでは画像のアスペクト比を変更することが可能です。
右サイドバーの「基本設定」でアスペクト比を変更できます。
基本設定をクリックすると、上図のように画像サイズを調整する画面が現れます。
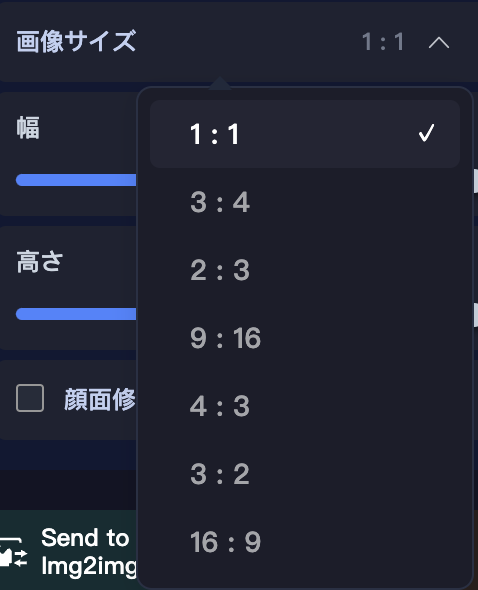
「画像サイズ」をクリックすると、アスペクト比の一覧が表示されます。
それをクリックすると、次回の生成画像はそのアスペクト比に従って作られます。
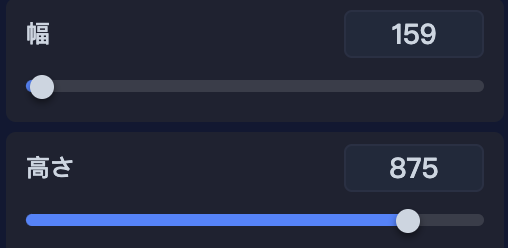
あるいは上図のように、メーターを自由に調整して、極端な画像サイズを作ることも可能です。
※幅・高さともに64 ~ 1024 の範囲まで対応しています。また、値が大きいほど、画像の生成に時間がかかります。
顔面修復について

基本設定の一部に、「顔面修復」という項目があります。
「顔面修復」にチェックを入れておくと、より詳細な顔の描写を行なってくれるようです。

上図は「顔面修復」をオンにして作成した「クラゲ帽子を被った少年 --auto --s2」です。

上図は「顔面修復」をオフ(デフォルト)にして作成した「クラゲ帽子を被った少年 --auto --s2」です。
しかし、基本的にはデフォルト通り「顔面修復」はオフのままで良いです。
オンにするとイラストのクオリティが低下することがあるようです。
ランダム生成を楽しむ
SeaArtでは、ランダム生成を行うことが出来ます。
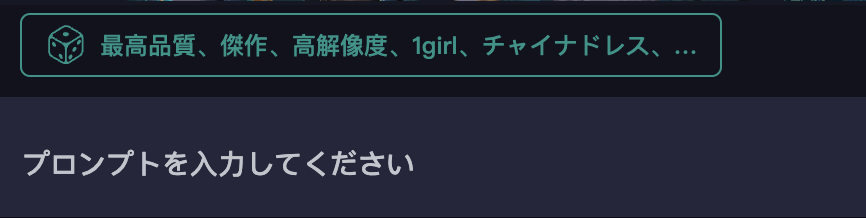
メッセージ欄のすぐ上にサイコロのマークがあります。
サイコロのマークをクリックするたびに、その右側に書かれている文章がランダムに変更されます。

サイコロのマークを押しると、その右側の文章が変更されました。
その文章をクリックします。

そうすると、その文章がそのままプロンプトとして、メッセージ欄にペーストされます。
このままエンターキーを押して生成してみます。

こういったものが完成しました。
ランダムで画像を生成してみると、思わぬ発見があるかもしれません。
検索もランダムで出来る

HOME画面から「AI広場」をクリックします。
そこには皆が作った画像が並べられています。
この画面の検索バーの右側にもサイコロマークがあります。
サイコロマークをクリックしてみます。
サイコロマークを押すと、即座にランダムな文章が検索バーに記載されて、一覧表示されます。
この機能を使って面白い画像を発見できるかもしれません。
他人の画像で「創作」する
SeaArtでは、他人の画像の内容をコピーして、自身の画像生成に活かすことが出来ます。
HOME画面から「AI広場」をクリックします。

画像一覧が表示されますので、気になった画像をクリックしてみます。
今回は右上の画像を選択します。
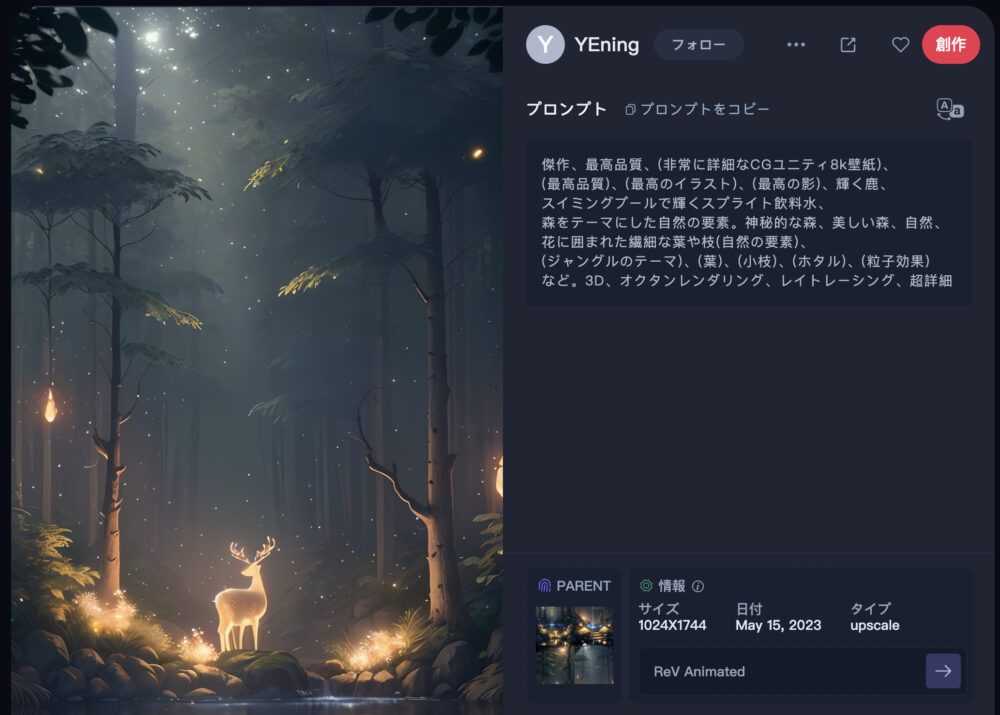
そうすると、左に拡大された画像が表示されて、右側に詳細なデータが表示されます。
- 作者名
- プロンプト
- 画像サイズ
- 作生年月日
- アップスケール情報
- モデル
上記についての情報が記載されています。

この画像を元に、自身で作業したい場合は、画面右上の「創作」ボタンを押します。

すると、即座に画像生成画面に遷移して、プロンプトがメッセージ欄にペーストされます。
さらに、画面右の各種パラメーターも、その画像が生成された状態を再現してくれます。
素晴らしい画像が、どのようなプロンプトやパラメーターで作成されたのかを学ぶことができます。

そのまま画像を生成して出来たものが上図になります。
元画像と似た画像を作ることが出来ます。
画像を保存する方法
作った画像を保存する方法について解説します。
個別に保存する

生成した画像は、左クリックで拡大した後に、右クリック→「名前を付けて画像を保存」でダウンロードすることが出来ます。
ボード(作品集)に保存する
画像をまとめる方法があります。
HOME画面の右上にある自身のアイコンをクリック、もしくはマイページを選択します。

すると、今まで生成してきた画像がすべて表示されています。
もし表示されていなければ、画面左上の「すべて」をクリックして、他の項目にした後に、もう一度「すべて」を押してください。

画面右上の矢印のマークをクリックします。

その状態で各画像をクリックすると、緑の枠線で囲われていきます。
画面右上の「移動」をクリックします。

移動の項目の下に「ボードを作成する」と記載がありますので、それをクリックします。
そうすると、作品集名を記入させられますので、適当に名前を付けます。
今回は「保存001」と付けました。
「作成」をクリックします。

すると、マイページに「保存001」が追加されました。
「保存001」をクリックすると、さきほど選んだ画像がこちらに移動しています。
このように、ボード(作品集)を作って、作品ごとにジャンル分けをしてアーカイブすることも出来ます。
ボード(作品集)から画像を保存
ボード(作品集)の画像一覧の各画像をクリックします。

クリックすると、このような画面になります。
画面右上の「…」をクリック→「画像を保存」を押すと、画像をダウンロードすることが出来ます。
他人の画像をダウンロードする
自分で作成した画像だけはなく、他人が作った画像もダウンロードすることが可能です。
HOME画面から「AI広場」をクリックします。

画像一覧が表示されますので、ダウンロードした画像をクリックします。
画面右上の「…」をクリック→「画像を保存」でダウンロードすることが可能です。
以上、ここまで述べてきたことがSeaArtの大まかな機能です。
以下ではモデルやコントロールネットなど、より深い機能について解説していきます。
モードについて
右サイドバーの「モード」について解説します。
「モード」は現在、
- デフォルト
- SeaArt 2.0
- Auto
上記3種類が用意されています。
元々は「Auto」になっていると思います。
「Auto」では、プロンプト等に応じて、適切なパラメーターを自動的に調整してくれるようです。
ただし、基本的には「SeaArt 2.0」に設定することをオススメします。
「SeaArt 2.0」は最新のSeaArtバージョンです(SeaArt V6のこと)。
高品質の画像を生成することが可能で、現在無料で使用することが出来ます(2023年6月19日現在)。
「Auto」でもSeaArt 2.0(--s2)を使用することがほとんどですが、モードを「SeaArt 2.0」に設定すると、多くの機能を自分好みに取り入れることが出来ます。
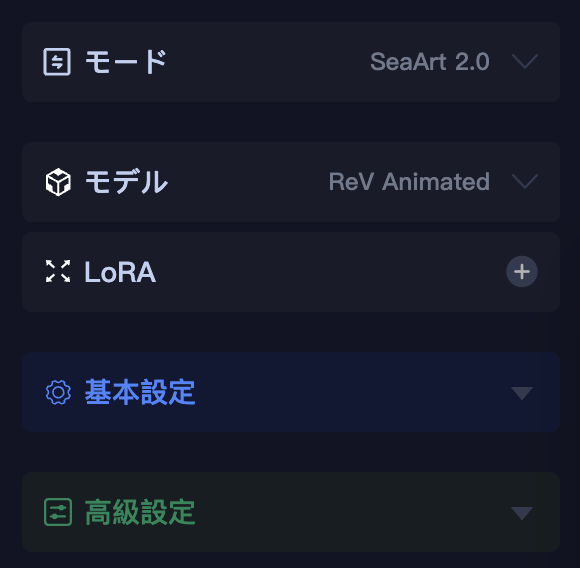
上図のように、モードを「SeaArt 2.0」(もしくは「デフォルト」)にすると、3つの項目が追加されます。
- モデル
- LoRA
- 高級設定
上記3つの項目は、画像生成に大きな影響を及ぼすため、自身で取捨選択・調整するほうが良いと思います。
モデル→LoRA→高級設定の順に解説していきます。
モデルについて
モデルとは、大量の画像を用いて学習したデータファイルのことです。
モデルを使用することによって、特定のスタイル(例:アニメ調やリアル調など)の画像生成が可能です。
モデルの場所について
画像生成画面から「モデル」を選ぶ
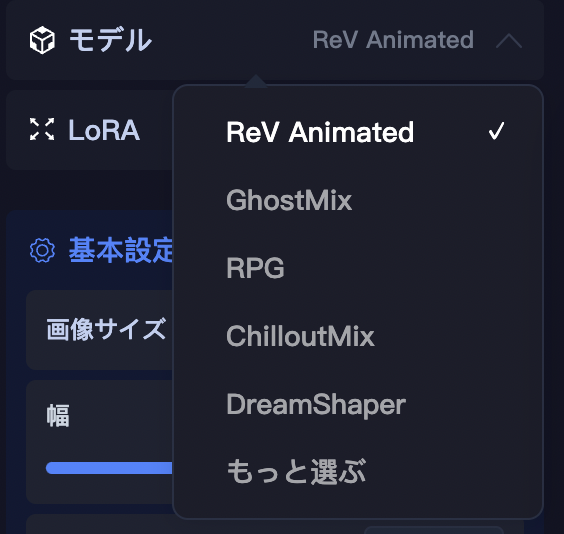
画像生成する画面の右サイドバーに、モデルという項目があり、そこから好きなモデルを選択することが出来ます。
(※前述しましたが、「モード」を「SeaArt2.0」もしくは「デフォルト」にしておくと「モデル」の項目が出現します。)
「もっと選ぶ」をクリックして、

画面上部にあるタブの「より多くの画像」を選択すると、「モデル」だけを集めた画像一覧が表示されます。

マウスを画像に重ねると、「モデル」の名前などが表示されます。
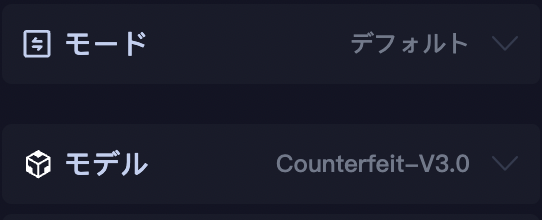
その画像をクリックすると、画像生成の画面に遷移して、「モデル」の項目が選択したモデルに更新されます。
AI広場から「モデル」を選ぶ

その他にも「モデル」を選ぶ方法があります。
AI広場から、
画面右上の「作品」をクリックして、
「Checkpoint」に変更すると、モデル一覧が表示されます。

上図がAI広場にて、「Checkpoint」を選んで、モデルを一覧表示したところです。
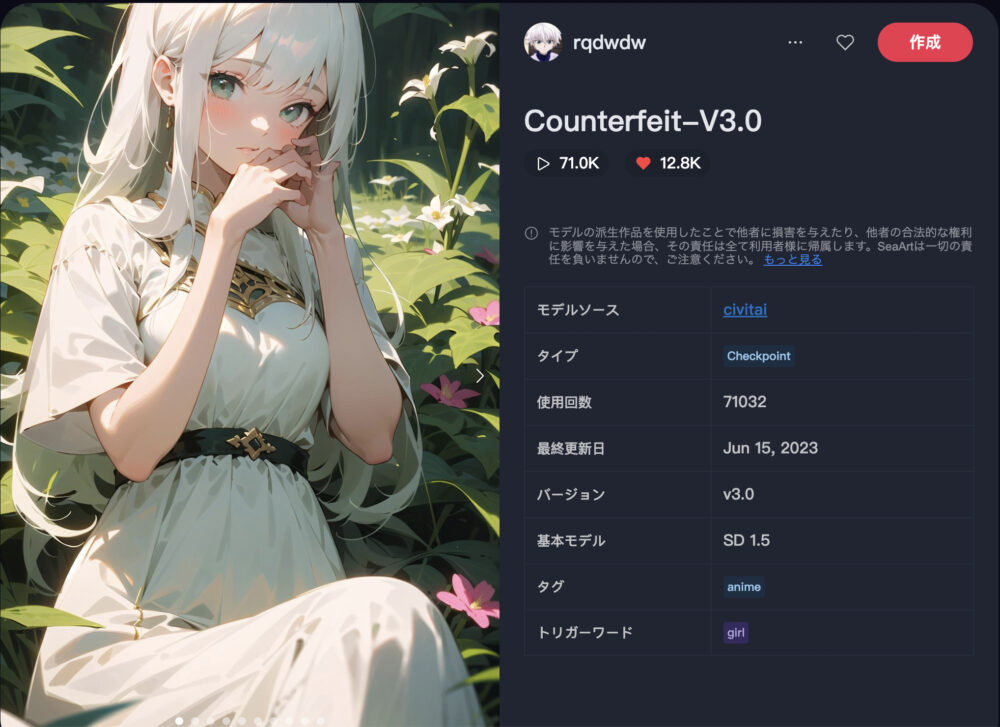
各画像をクリックして、モデルの詳細なデータを見ることが出来ます。
画面右上の「作成」をクリックすると、

その画像のプロンプトとモデルが選択された状態で、画像生成画面に遷移出来ます。
モデルの人気ランキング
「モデル」は多くの種類が作成されています。
CIVITAI(https://civitai.com/)や、Hugging Face(https://huggingface.co/models?pipeline_tag=text-to-image&sort=likes)にて公開されています。
その中にも人気のモデルがありますので、SeaArt上での❤️獲得数順に並べてご紹介したいと思います(2023年6月16日時点での❤️数に準じています。
※アダルト系のモデルは除外しています。紹介漏れもあります。
※モデル使用時の注意点等については、各サイトにてご確認ください。
ChilloutMix ❤️33.3K
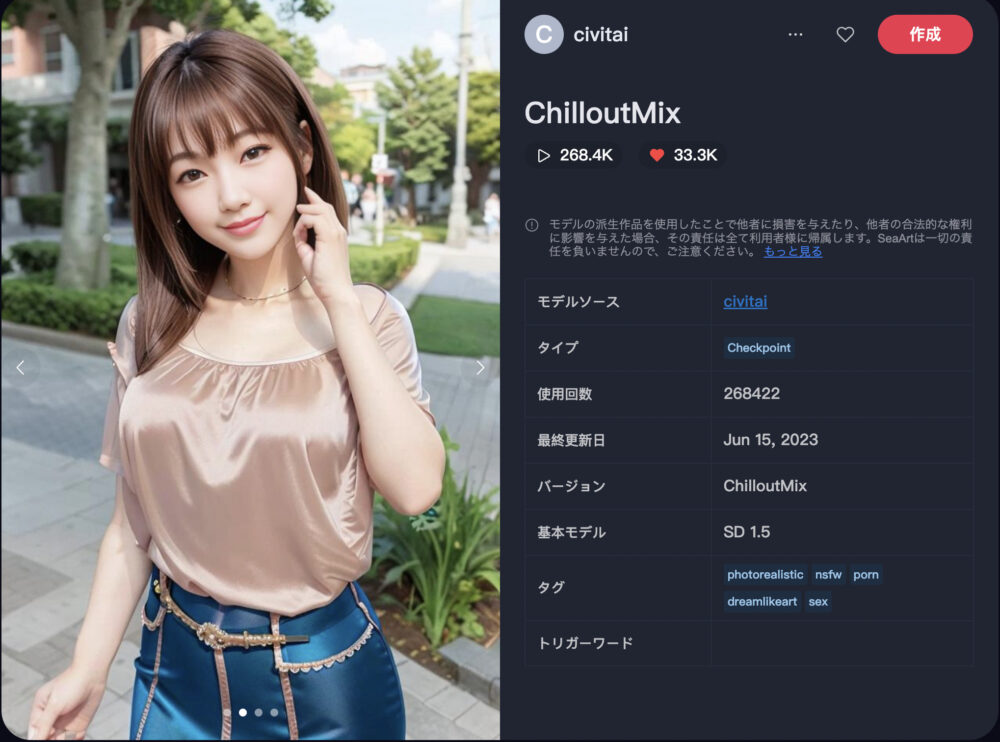
最も人気があるのが、ChilloutMixです。
リアルなアジア人女性の画像を生成することが出来るのが特徴です。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++ 2M Karras DPM++ SDE Karras | 25-50 | 7 |


Counterfeit-V3.0 ❤️12.8K
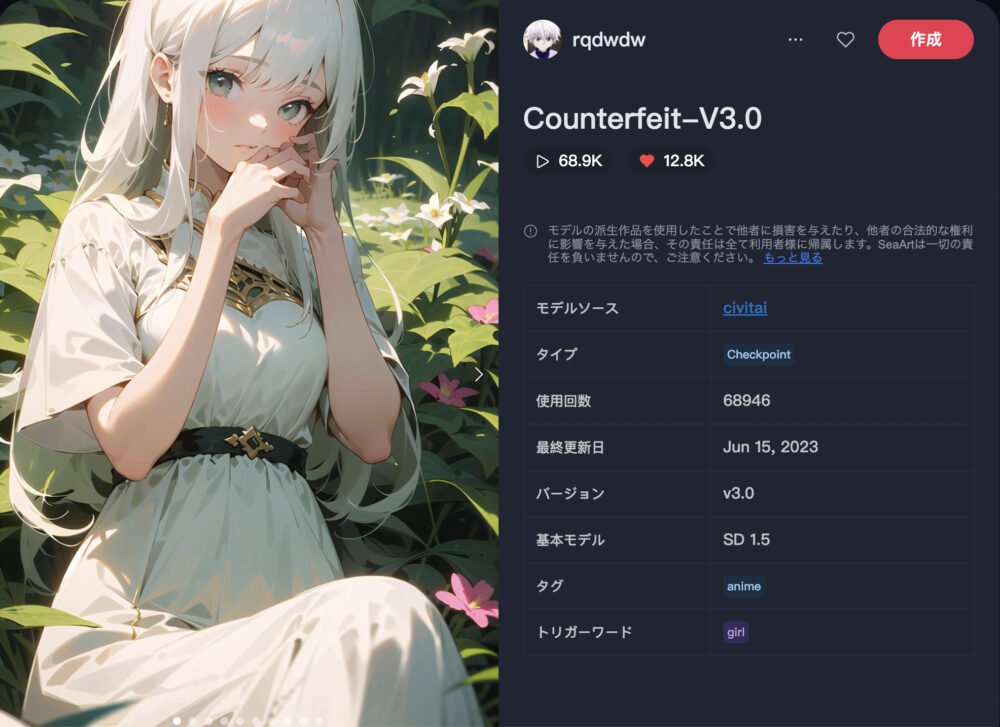
Counterfeit-V3.0は、高品質のアニメ系イラストを生成できるのが特徴です。
少女や、美しい背景描写に定評があります。


Deliberate ❤️10.8K

Deliberateは、高品質の実写系のモデルです。
多くのプロンプトに対応できますが、アジア人の画像生成には弱いです。


ChikMix ❤️10.4K
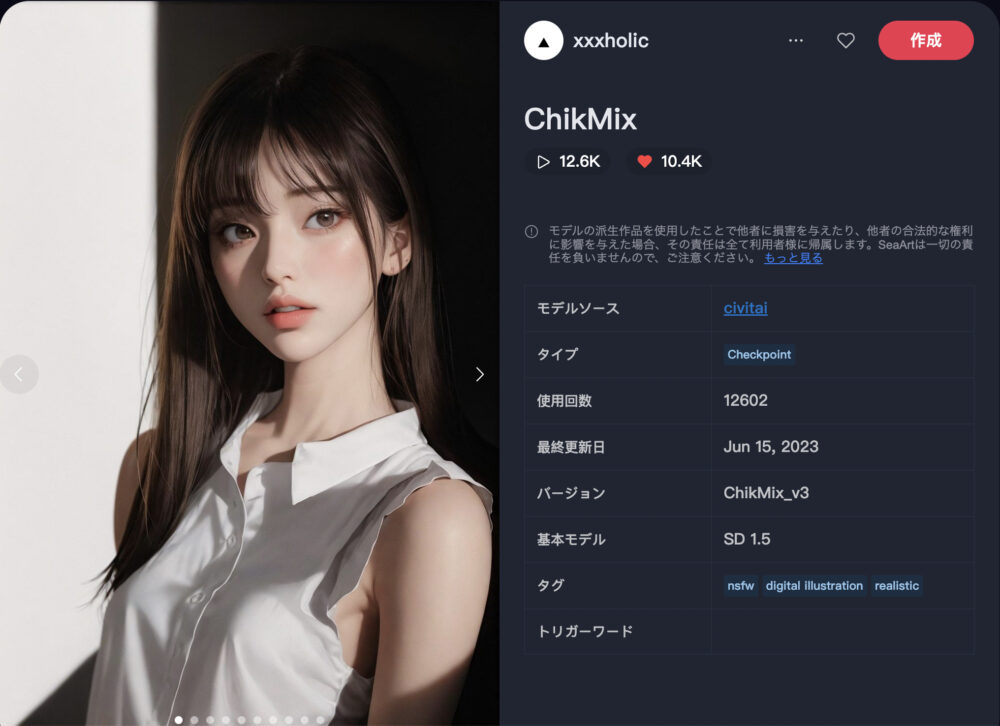
ChikMixは2.5Dの人物描写に優れたモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++ SDE Karras | 28 | 7 |


DreamShaper ❤️9.3K

DreamShaperは、絵画のような画像を生成できる特徴があります。


Pastel-Mix [Stylized Anime Model] ❤️8.4K
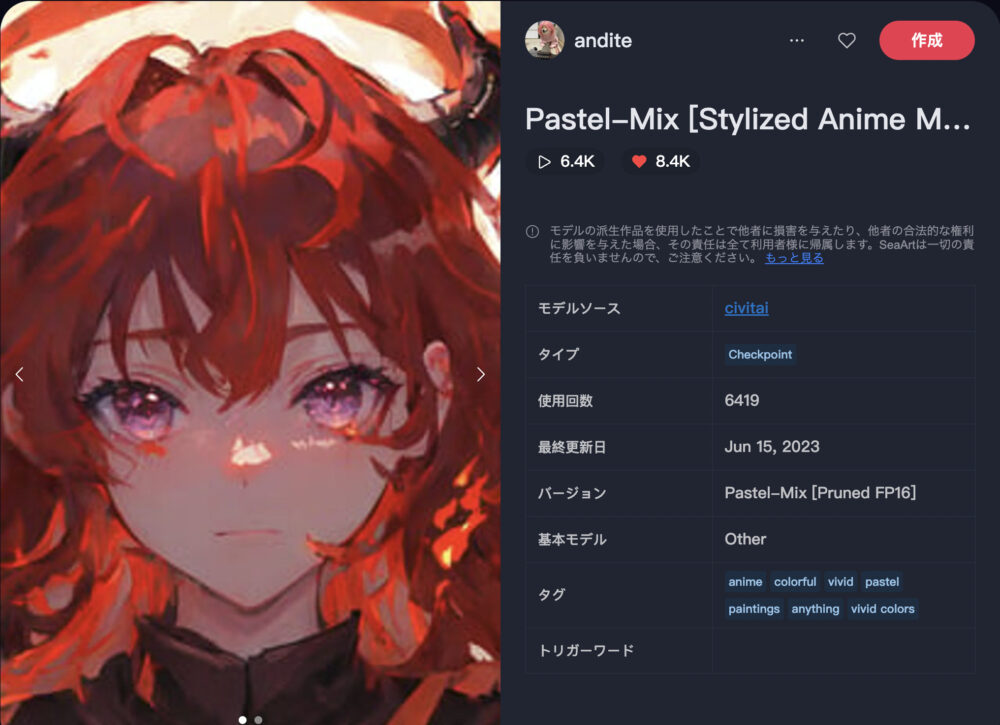
Pastel-Mix [Stylized Anime Model]は、パステル調のアート描写が特徴のモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++ 2M Karras | 20 | 7 |


Realistic Vision V2.0 ❤️7.9K
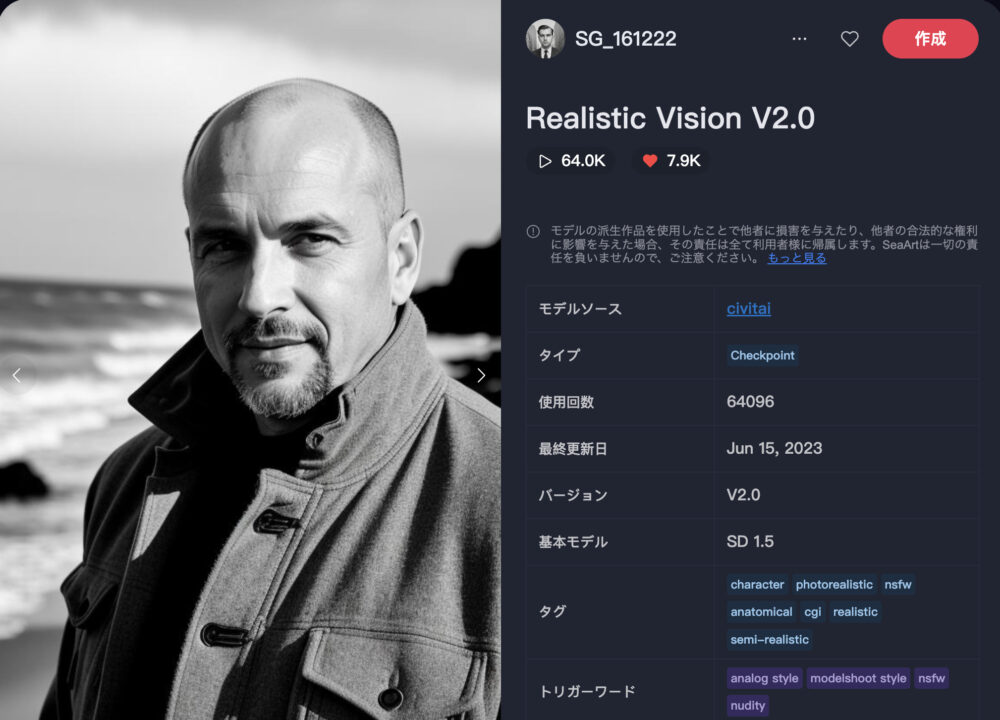
Realistic Vision V2.0は、リアルな描写を得意とするモデルです。
リアルな人物や動物描写の他に、多人数の構図にも対応しています。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| Euler a DPM++ 2M Karras | 25 | 3,5 - 7 |


Cetus-Mix ❤️8.0K
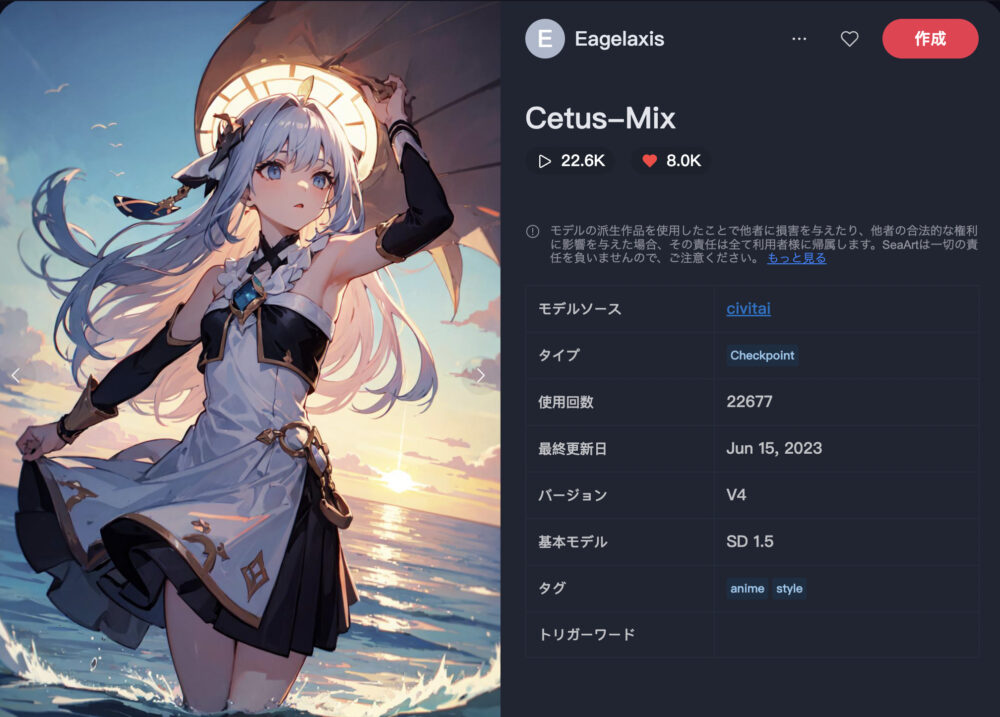
Cetus-Mixは、アニメ調のキャラクターと背景描写に優れたモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++2M Karras | ? | 4-8 |


RealDosMix ❤️7.2K

RealDosMixは、リアル調の画像生成が得意なモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++SDE karas | ? | ? |


DosMix ❤️6.4K
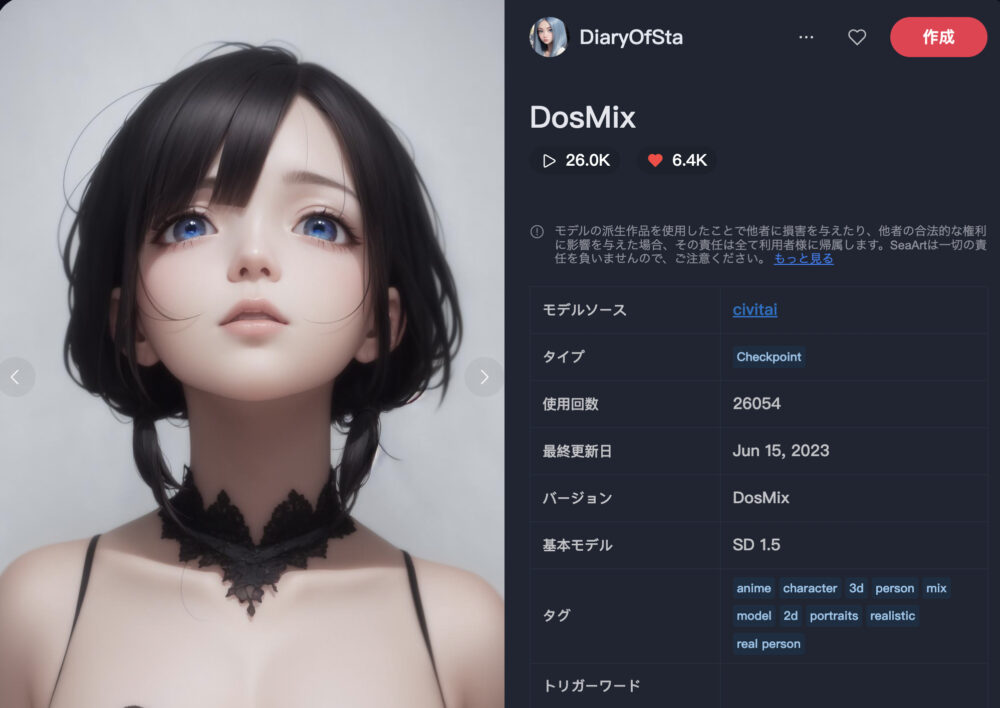
DosMixは、2.5D描写に優れたモデルです。


国风3 GuoFeng3 ❤️6.2K

国风3 GuoFeng3は、中華系ゲームのキャラデザインを特徴とする2.5Dモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++SDE karas | 30 または 50 | ? |


FaceBombMix ❤️5.6K
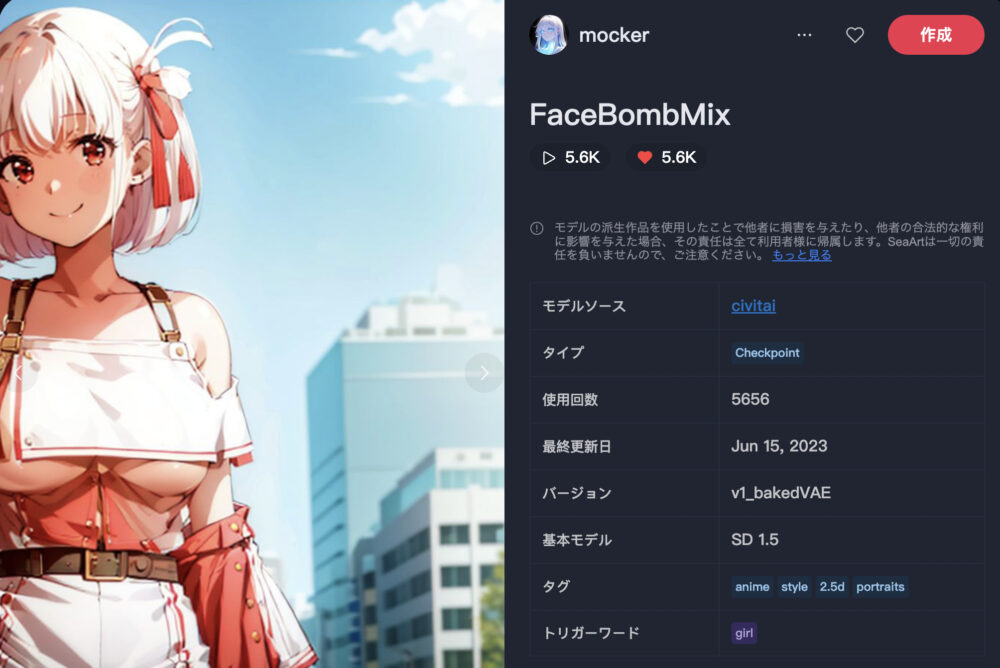
FaceBombMixは、アニメ調と2.5Dを得意としたモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++SDE karas | 32 (24 ~ 32 任意) | 9 (7 ~ 9、お好みで) |

KoreanStyle2.5D ❤️5.3K
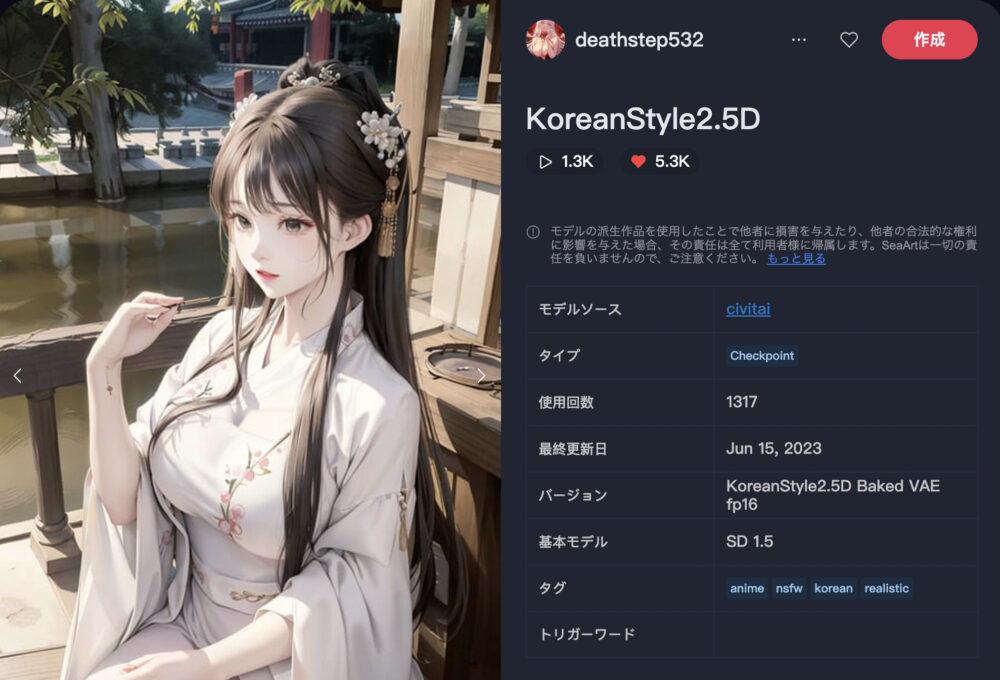
KoreanStyle2.5Dは、韓国系のモデルを2.5D化したような画像を生成することが出来ます。

NeverEnding Dream (NED) ❤️5.1K

NeverEnding Dream (NED)は、DreamShaper(前述した絵画的なモデル)の強化版です。
キャラクターLoRAとの相性が良いのが特徴です。


ReV Animated ❤️4.8K
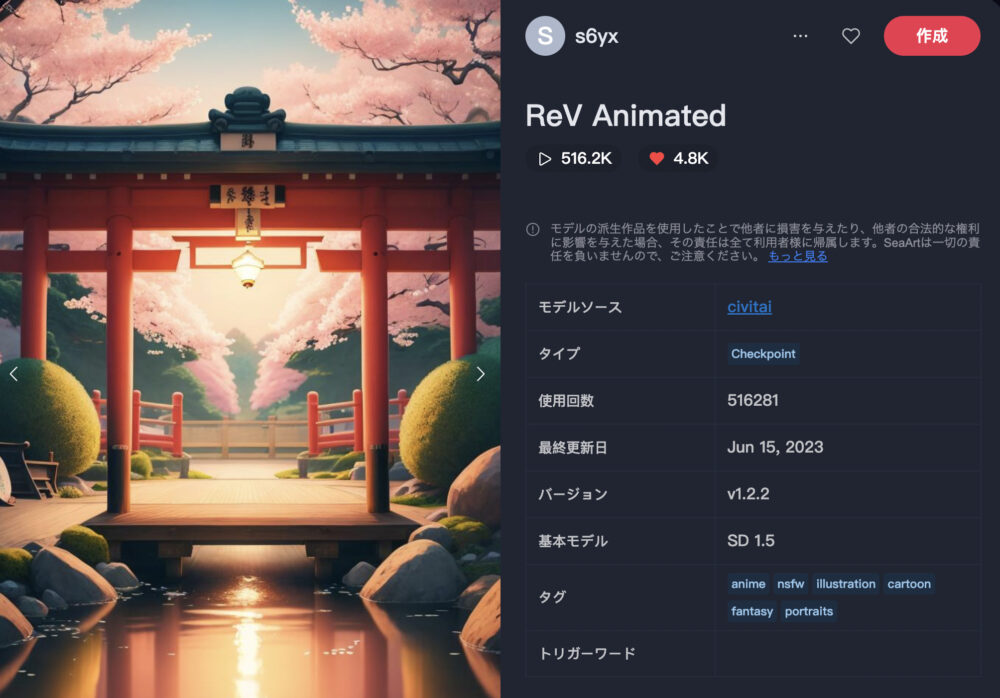
ReV Animatedは、アニメ調の画像生成に長けています。
ファンタジー風の画像も得意としています。
推奨画像サイズは以下のようになります。
- 512x512
- 512x768
- 768x512


MIX-Pro-V4 ❤️4.4K
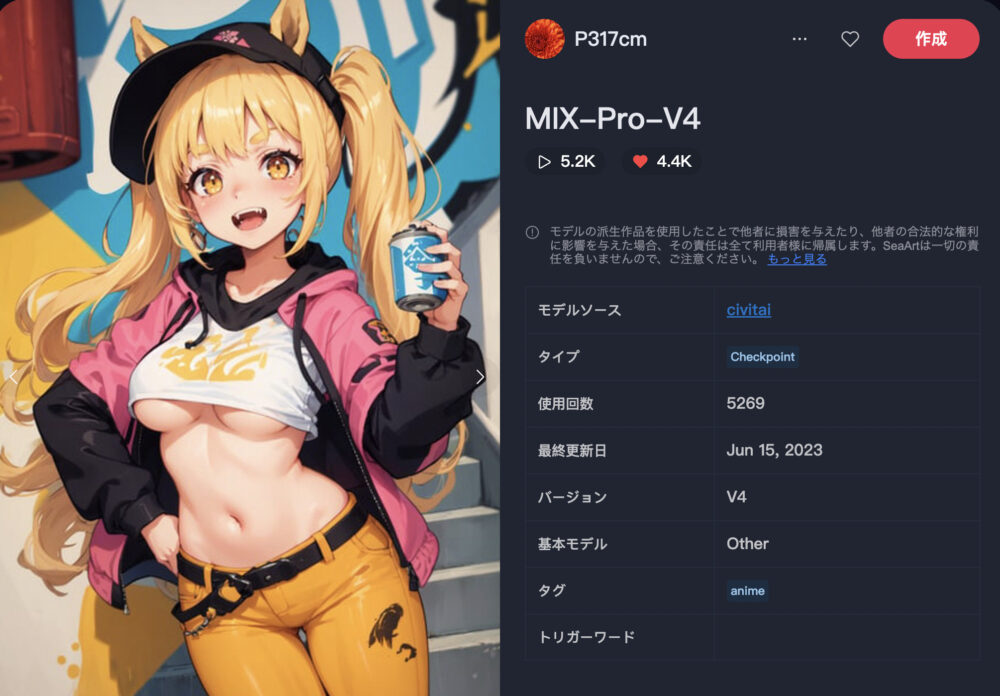
MIX-Pro-V4は、ビビッドな色使いのアニメ調の画像生成を得意としています。


Lucky Strike Mix ❤️4.2K
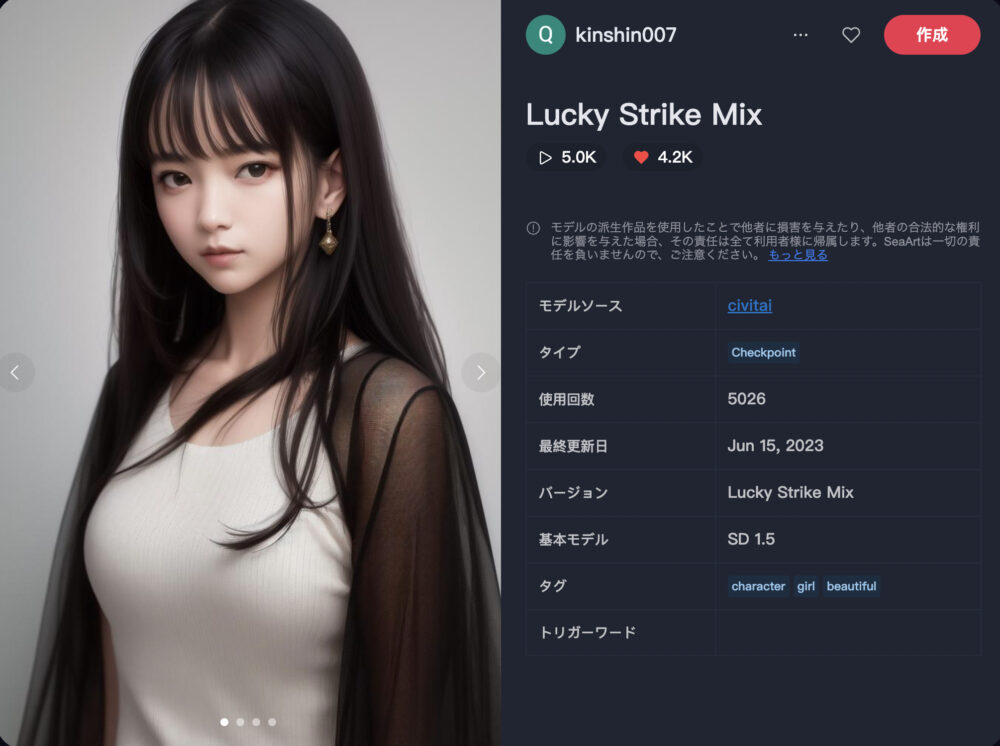
Lucky Strike Mixは、非常にスレンダーで、9頭身の女性を描写する特徴があります。

Night Sky YOZORA Style Model ❤️3.8K
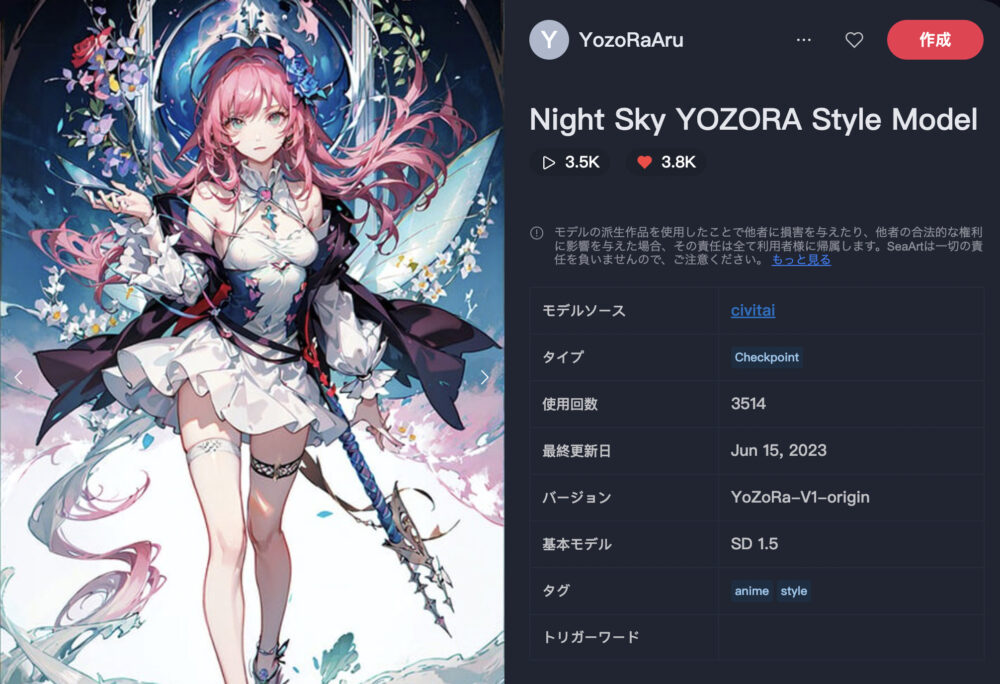
Night Sky YOZORA Style Modelは、美しいアニメ調のイラストを生成できるモデルです。

他のおすすめモデル
❤️数は少ないですが(バグなのかもしれませんが)、人気・オススメのモデルをご紹介します。
BRA(Beautiful Realistic Asians)
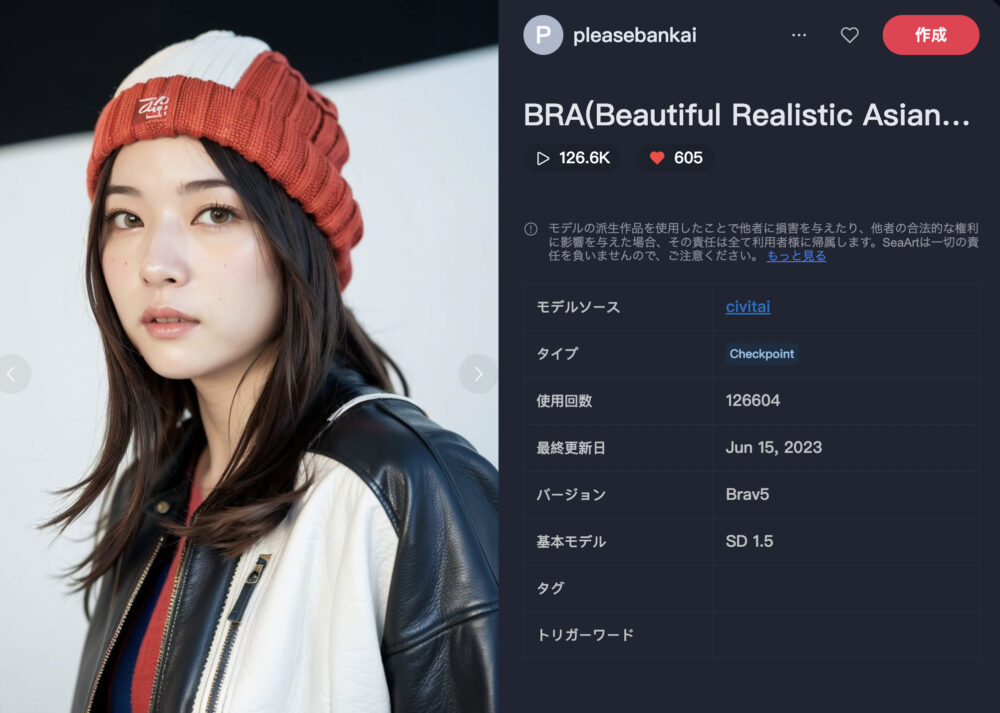
BRA(Beautiful Realistic Asians)は、アジア人描写に特化したモデルです。
生活感のあるリアルな描写にも定評があります。


A-Zovya RPG Artist Tools
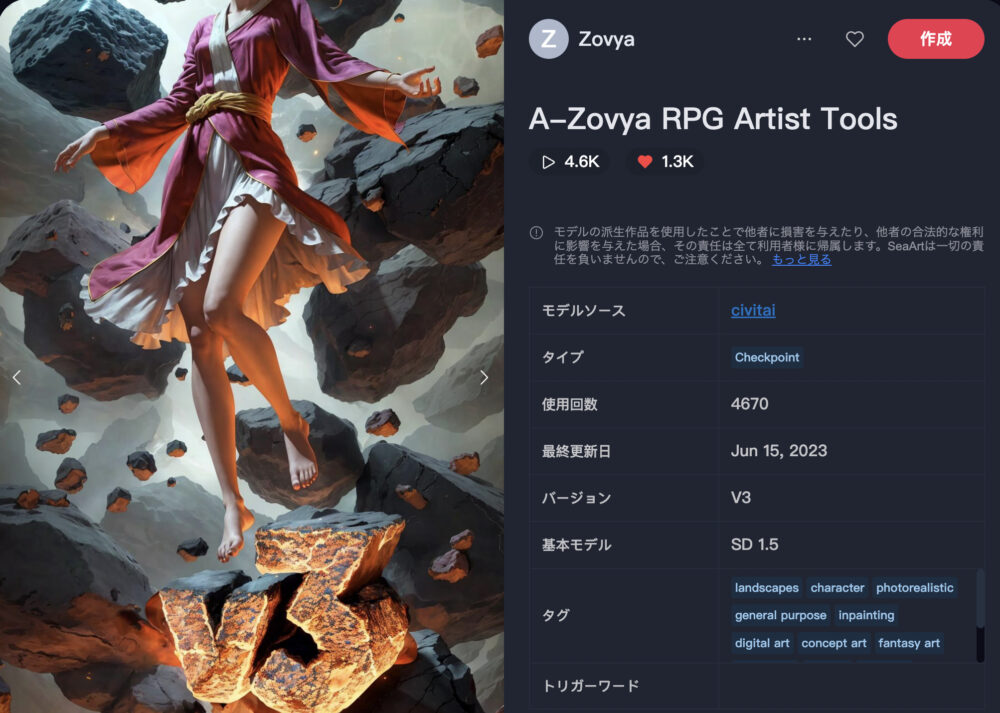
A-Zovya RPG Artist Toolsは、RPGのキャラクターや、クリーチャー、コンセプト画像を生成することが得意なモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++ 2M Karras alt Karras DPM++ SDE Karras | 20~40 | 6-8 |


OrangeChillMix

OrangeChillMixは、アニメ調から実写寄りのイラストを生成できるモデルです。


MechaMix
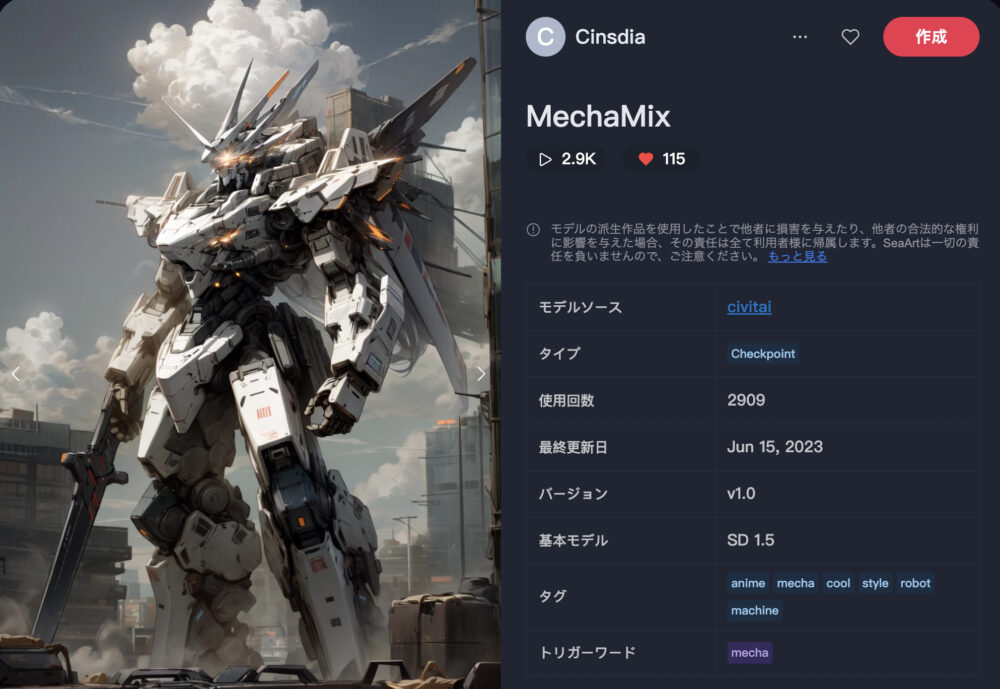
MechaMixは、メカ・ロボット系の画像に特化したモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++ 2S a Karras | 20 | 7 |
Three Delicacy Wonton (三餡馄饨Mix)
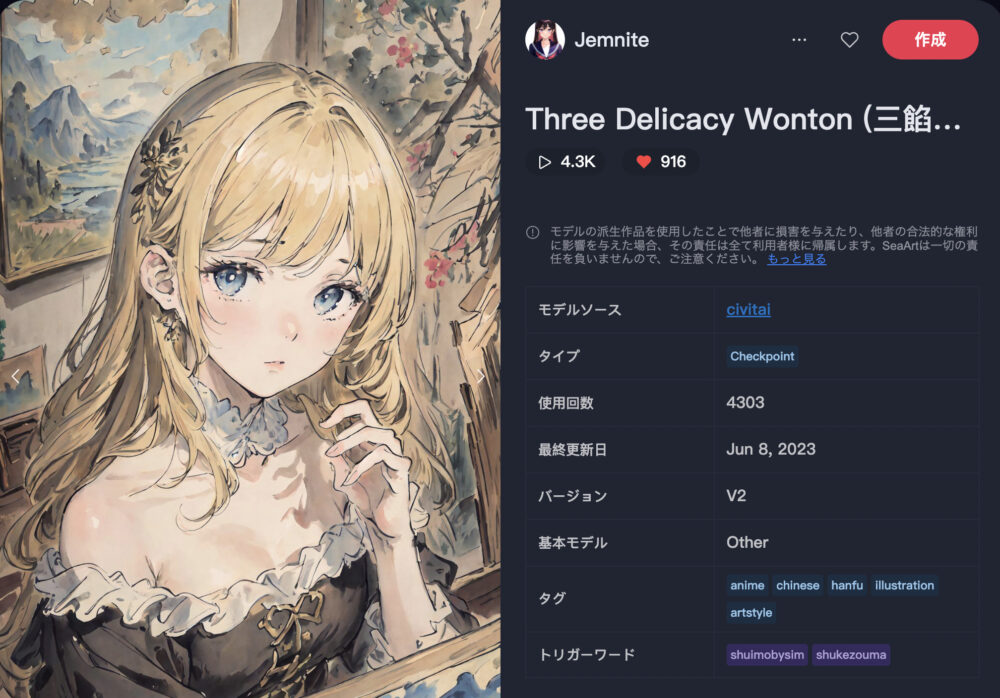
Three Delicacy Wonton (三餡馄饨Mix)は、水墨画を特徴とするモデルです。


AbyssOrangeMix3 (AOM3)
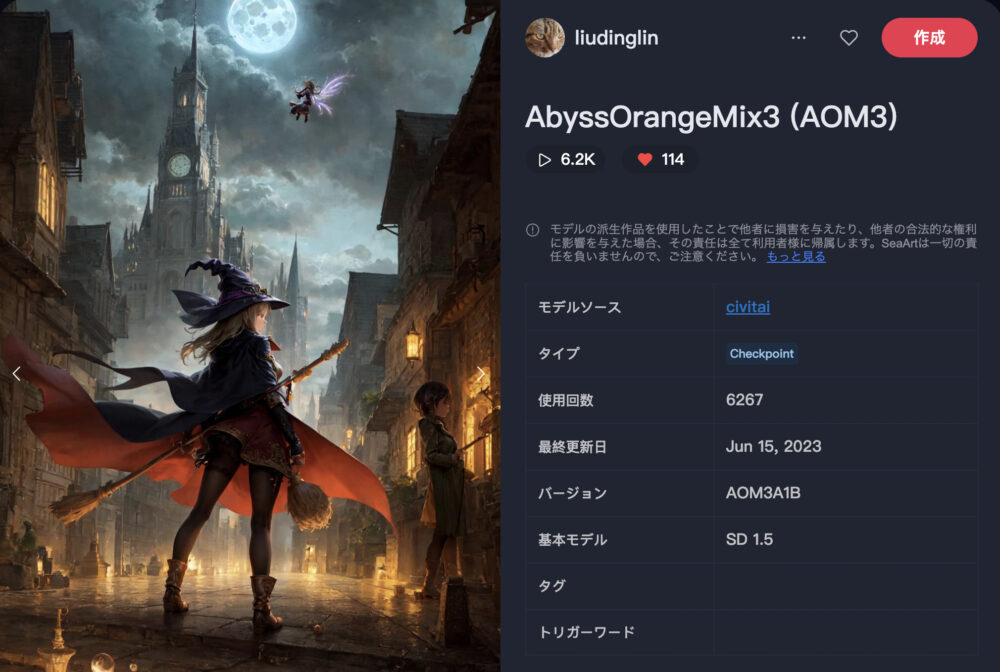
AbyssOrangeMix3 (AOM3)は、リアルな質感の少女のイラストを生成することが出来るモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++ 2M Karras DPM++ SDE Karras | ? | ? |


MUSE_v1
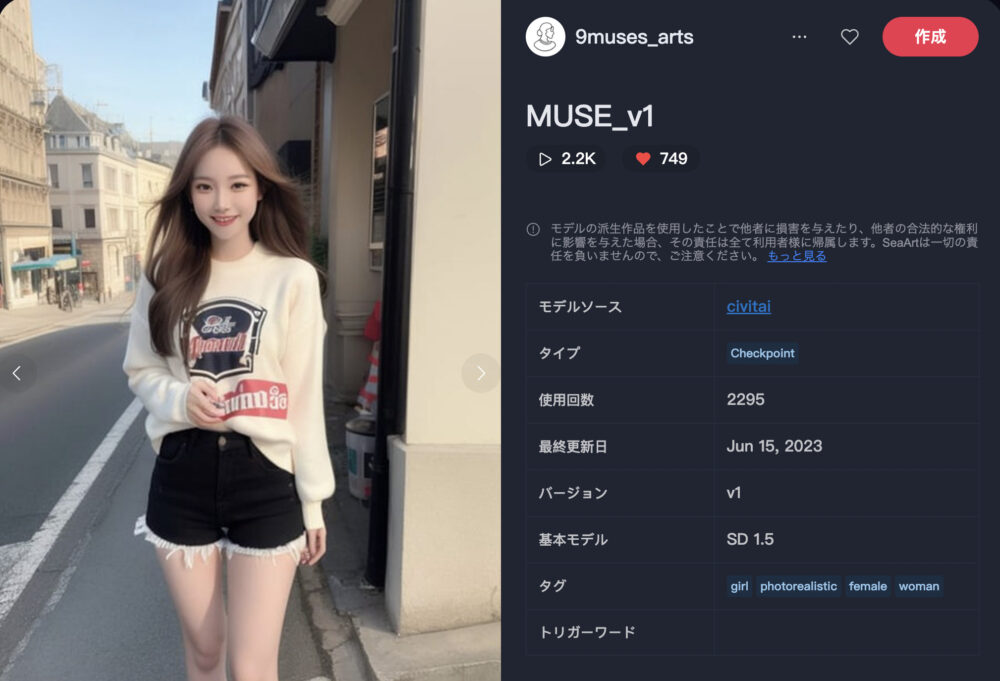
MUSE_v1は、リアル調の日本人の画像を生成することが得意なモデルです。


maturemalemix
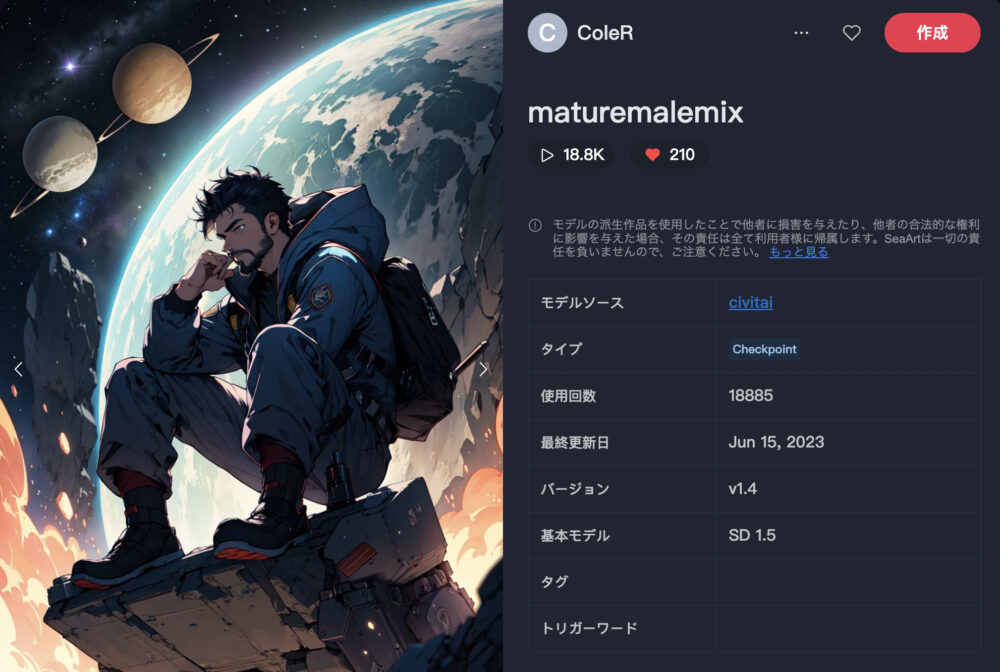
maturemalemixは、男性のイラスト生成を得意としたモデルです。


LOFI
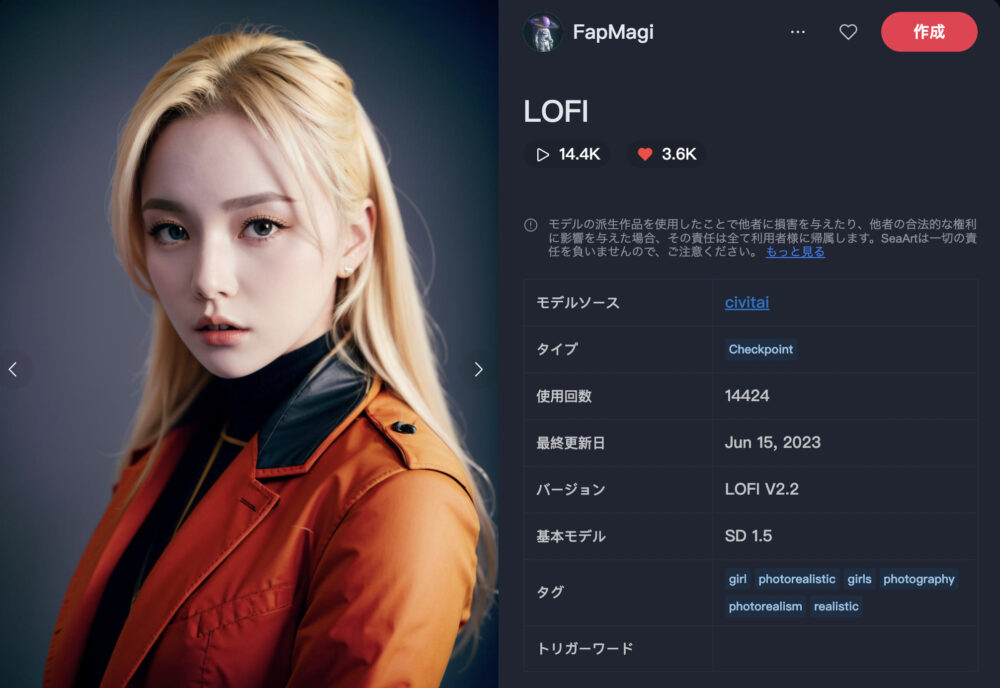
LOFIは、リアル調のアジア人の画像生成を得意とするモデルです。


majicMIX realistic

majicMIX realisticは、アジア系の女性画像生成を得意とするモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| Euler a Euler DPM++ 2M Karras DPM++ SDE Karras | 20~40 | 6-8 |

majicMIX fantasy

majicMIX fantasyは、美しいファンタジーのイラスト生成が特徴的なモデルです。


MeinaMix
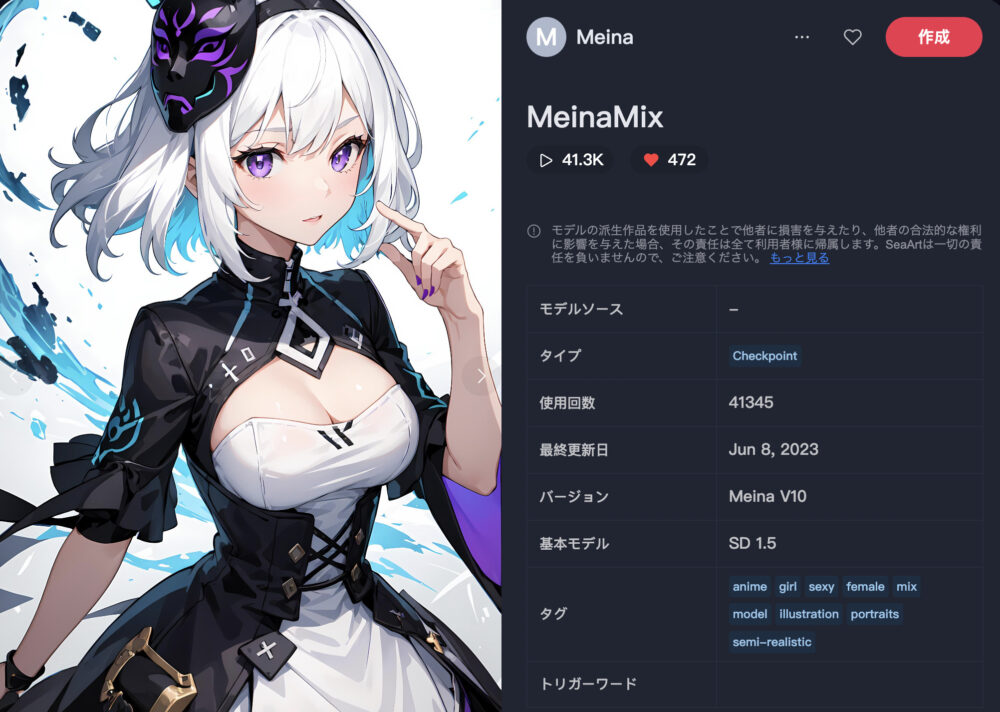
MeinaMixは、アニメ調のイラストに特化したモデルです。
推奨画像サイズは以下のようになっています。
- 512x768
- ポートレートの場合は 512x1024
- 風景の場合は 768x512、1024x512、1536x512
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| Euler a DPM++ SDE Karras DPM++ 2M Karras | 40 ~ 60 30 ~ 60 20 ~ 60 | 4 ~ 11 |


GhostMix

GhostMixは、SF系の画像生成が得意な2.5Dモデルです。
推奨画像サイズは「512,768」となっています。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++ series | 20-30 | 5-7(7 is best) |


RPG
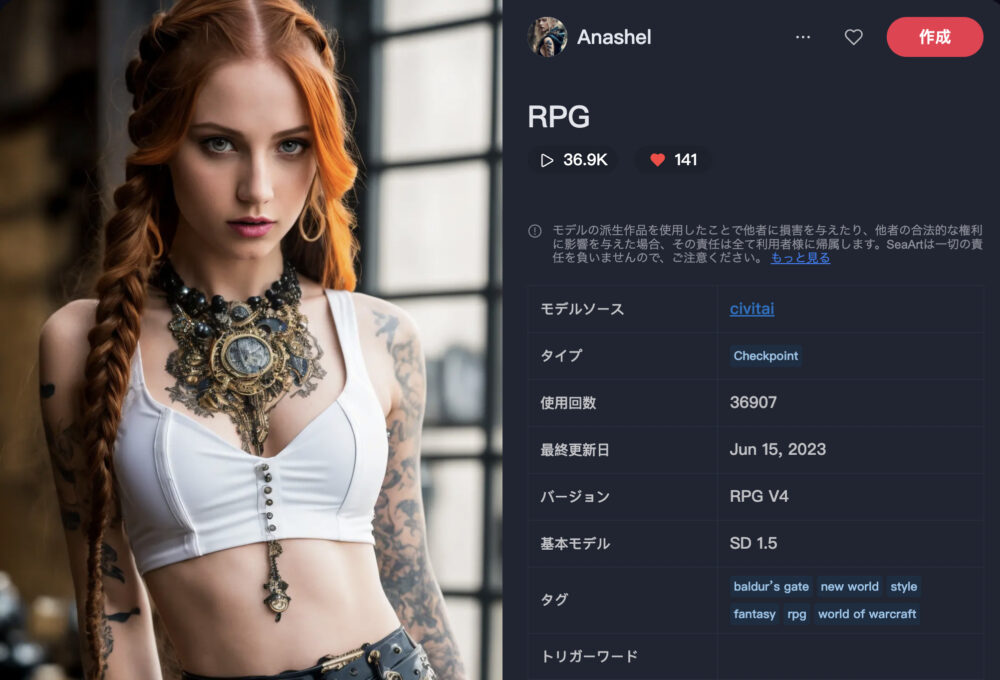
RPGは、ファンタジー系の画像生成が特徴のモデルです。


CyberRealistic
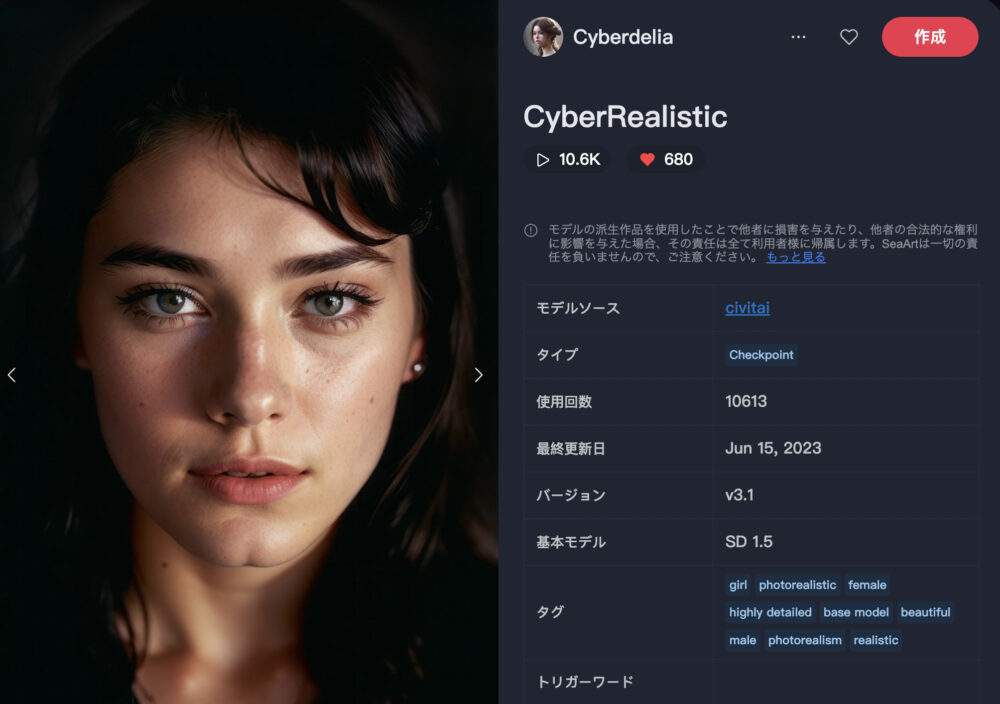
CyberRealisticは、写実的な画像生成を得意とするモデルです。

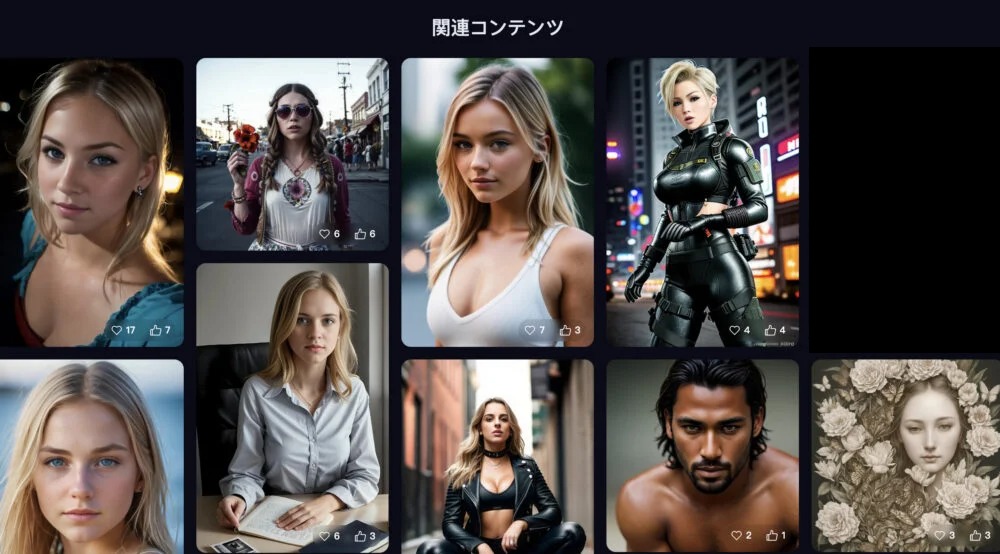
ToonYou

ToonYouは、漫画・アニメ調のイラストに特化したモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++ 2M Karras - バランス用 DPM++ SDE Karras - 品質用 | 25 | 8 |


万象熔炉 | Anything V5
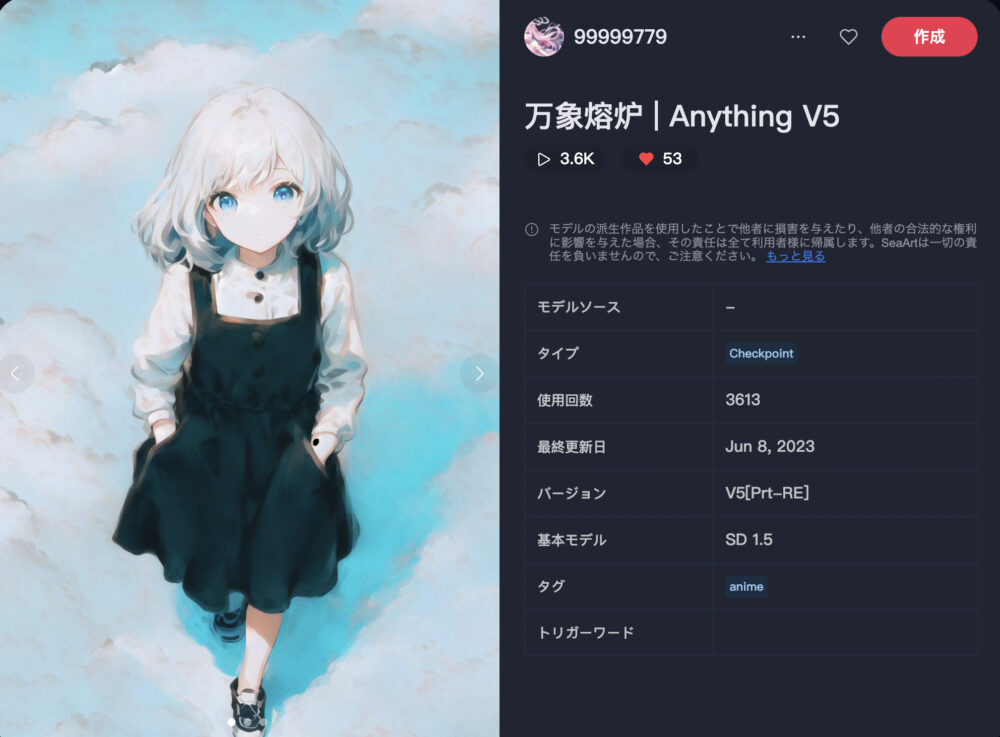
万象熔炉 | Anything V5は、アニメ調の画像生成に特化したモデルです。

yden
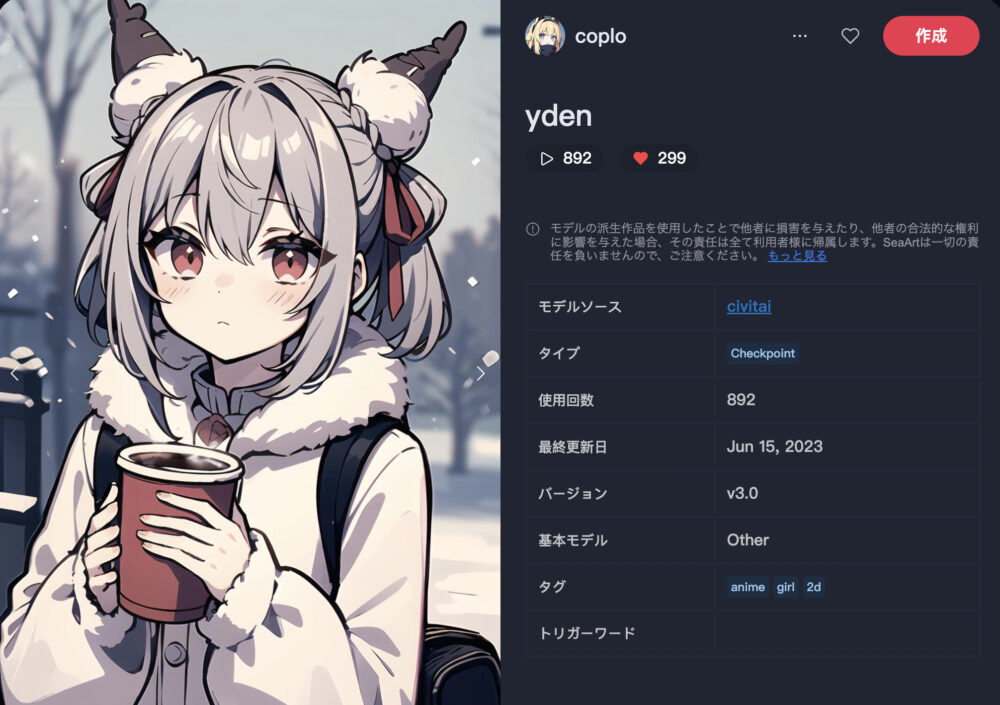
ydenは、独特なタッチのアニメ画像生成が特徴的なモデルです。
| 推奨サンプリング | 推奨ステップ | 推奨CFG |
| DPM++ 2M Karras | 22 | 7 |

LoRAについて
LoRA(Low-Rank Adaptation)とは、大型モデルを微調整する小規模なモデルです。
既存のモデルに新しい画像を追加学習させることで、お気に入りのモデルを自分好みにカスタマイズすることが出来ます。
LoRA モデルは一般的に、スタイル LoRA とキャラクター LoRA に分類されます。
- スタイル LoRAは、 指定されたアート スタイルに沿った画像を生成します。
- キャラクター LoRAは、指定されたキャラクターに似た画像を生成します。
特定のアニメキャラクターなどに似せるLoRAや、背景を学校にするLoRAなど色々とありますので、お気に入りのものを探してみましょう。
LoRAの場所について
SeaArtのLoRAの場所について解説します。
生成画面から選択する方法

HOME画面の最上部の「AIイラスト生成」をクリックします。
画面右のサイドバーの「モード」をクリックします。
モードを「デフォルト」か「SeaArt2.0」に変更します。
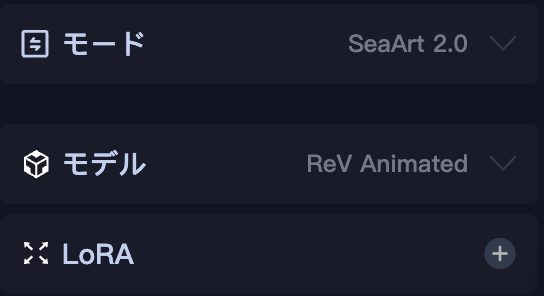
そうすると、「モデル」と「LoRA」の項目が出現します。
そこの「LoRA」をクリックします。
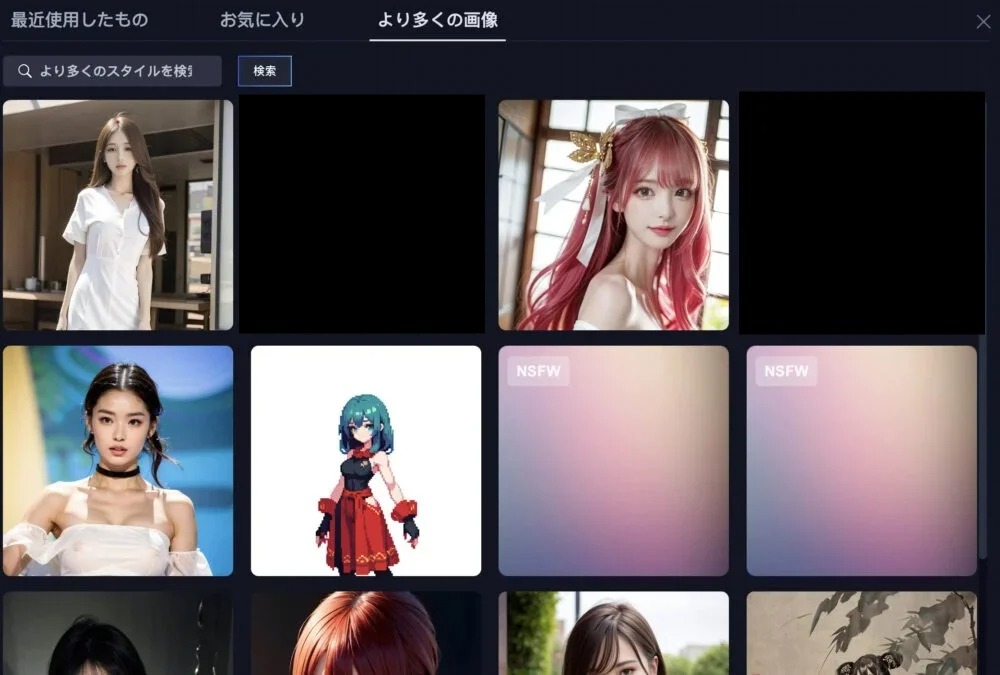
タブの「より多くの画像」や「検索」などを用いて、好みのLoRAを探すことが可能です。
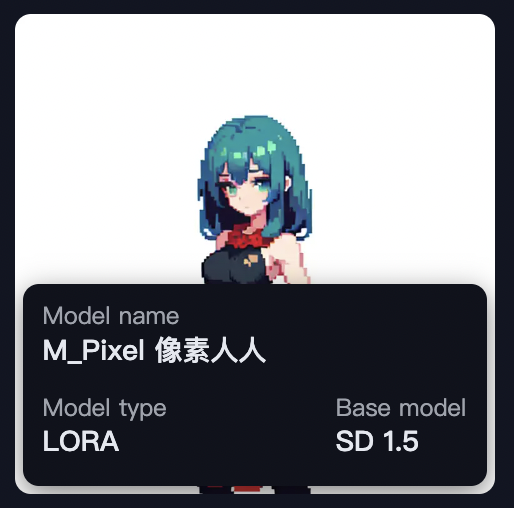
画像にマウスを重ねると、LoRAの名称などが表示されます。
このドット絵の画像をクリックしてみましょう。
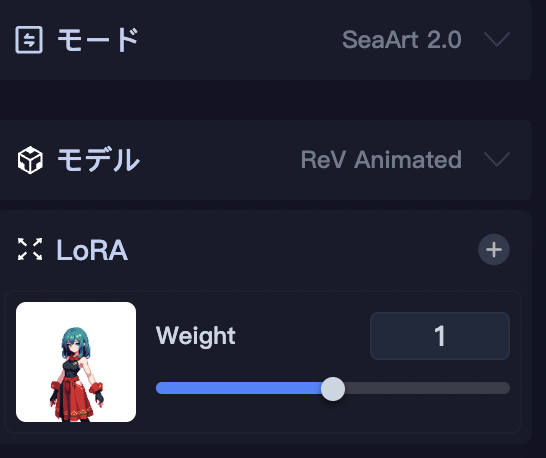
そうすると、LoRAの項目に、さきほどクリックしたLoRAが設定されました。
AI広場から選択する方法
他に、AI広場からLoRAを選択する方法があります。
HOME画面の最上部の「AI広場」をクリックします。
右上の「作品」をクリックして、
LoRAを選択します。
そうすると、LoRAだけが並べられて一覧表示されます。

さきほどの、ドット絵のLoRAをクリックしてみました。
詳細なデータが記載されています。
画面右上の「作成」をクリックします。
すると、画像生成の画面に遷移します。
メッセージ欄には、さきほどの画像を作ったプロンプトがペーストされています。
また、右サイドバーには、モデルと、LoRAが設定されています。
LoRAを試してみる
まずはLoRA無し
さきほどご紹介した、majicMIX realisticを使用したモデルで、まずはLoRAを使用せずに画像を生成してみます。

プロンプト「(傑作、最高品質)、女性、全身」で出来た画像です。
LoRAは使用していません。
次に、LoRAを使用して作成してみます。
LoRAを選択
今回使用するLoRAは上図のものです。
画像をドット絵にする効果があります。
Weightについて
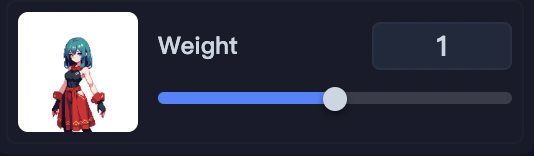
また、LoRAには「Weight」というものがあります。
デフォルトは1に設定されており、0-2の範囲を取ります。
- この値が大きければ大きいほど、LoRAの影響が大きくなります。
- この値が小さければ小さいほど、LoRAの影響が小さくなります。
LoRAをWeight別に出力
LoRAを使用して、Weight別に画像生成してみます。
プロンプトはいずれも「(傑作、最高品質)、女性、全身」で、モデルはmajicMIX realisticを使用しています。

Weight 0.5で作成しています。
ドット絵っぽくなっています。

Weight 0.75で作成しています。
ほぼ完全にドット絵になりました。

Weight 1で作成しています。
Weightが1になると、原型をとどめ無くなってしまいます。

Weight 1.5では画像が完全に崩壊します。
使用するLoRAによってWeightの影響度は変わってきますので、公式サイトなどを参照にしながら調整してみてください。
LoRAは3つまで同時に使用可能
LoRAは最大3つまで同時に使用可能です。
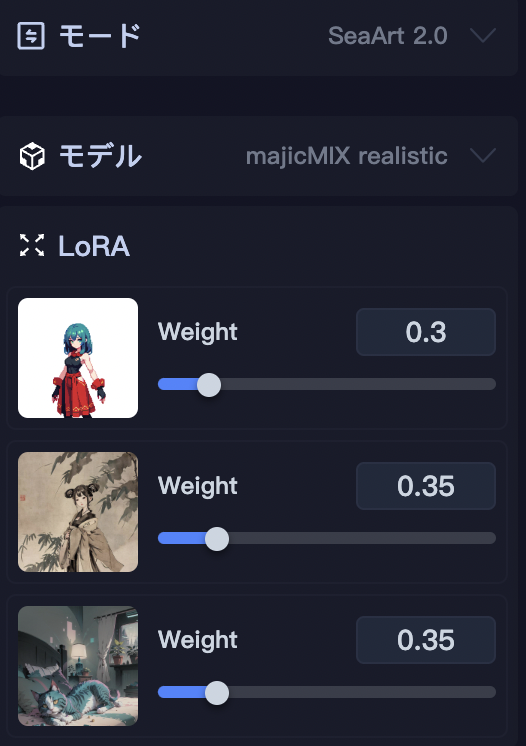
このように3つのLoRAを指定します。

プロンプト「(傑作、最高品質) 女性 全身」。モデルはmajicMIX realisticを使用。
各LoRAが影響しあった画像を作成することが出来ます。
高級設定について
SeaArtの「高級設定」について解説します。
高級設定の場所について
HOME画面の最上部の「AIイラスト生成」をクリックします。
画面右のサイドバーの「モード」をクリックします。
モードを「デフォルト」か「SeaArt2.0」に変更します。
そうすると、「高級設定」の項目が出現します。
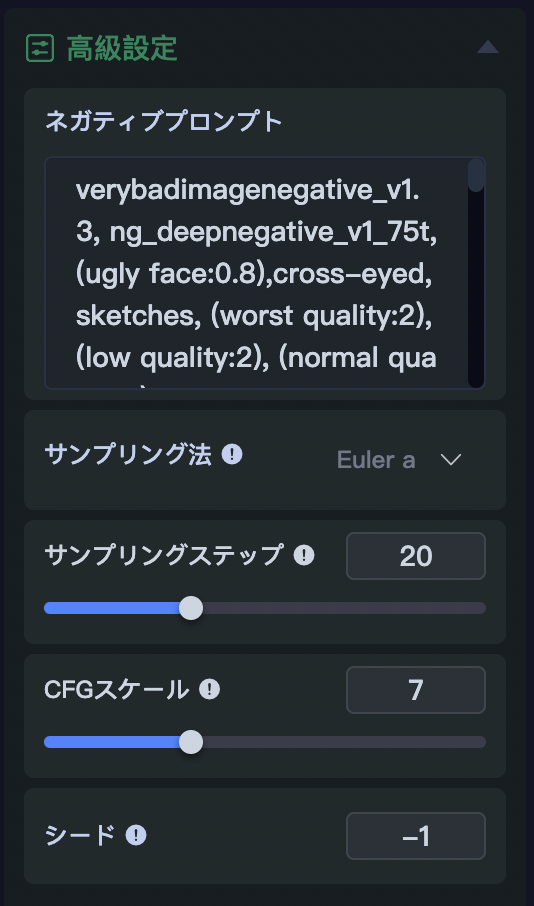
高級設定をクリックすると、
- ネガティブプロンプト
- サンプリング法
- サンプリングステップ
- CFGスケール
- シード
以上の5項目が表示されます。
以下では、それら5項目について解説していきます。
※各項目について、使用するモデルの推奨パラメーターを各公式サイトで発表していることがあります。各自ご確認ください。
ネガティブプロンプトについて
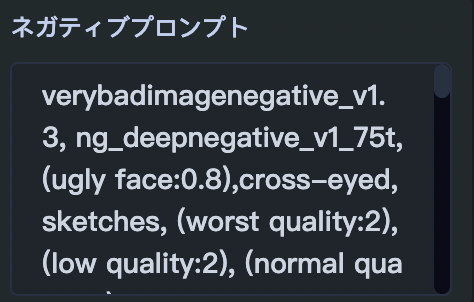
ネガティブプロンプト欄には、生成画像から除外したい事柄を記入します。
普通のプロンプトとは真逆の効果を及ぼします。
帽子をかぶって欲しくない場合は、「hat」と記入しておくと、帽子をかぶらなくなりやすいです。
元々ネガティブプロンプトが入っている
SeaArtでは、以下のようなネガティブプロンプトがデフォルトで入っています。
これらは、画像のクオリティを高めたり、人体の奇形を防止したりするための、一般的によく使われるネガティブプロンプトです。
強調構文を使用可能
ネガティブプロンプトでも強調構文を使用できます。
((monochrome))などのように、()で強調したり、(worst quality:2)のように「:数字」で強調したりできます。
強調すると、そのネガティブプロンプトは画像はさらに出現しづらくなります。
サンプリング法について

サンプリング法について解説します。
サンプリング法(サンプラー)とは?
そもそもサンプリングとは何でしょうか?
まずは、画像を生成する際の簡単な流れを以下に示します。
- 画像を生成するために、ステイブル・ディフュージョン(Stable Diffusion)では、完全にランダムな画像を生成します。
- 次に、画像のノイズを推定します(Predicted noise)。
- そして予測されたノイズを画像から差し引きます。
- このプロセスを十数回繰り返します。
- 最終的にクリーンなイメージが得られます。
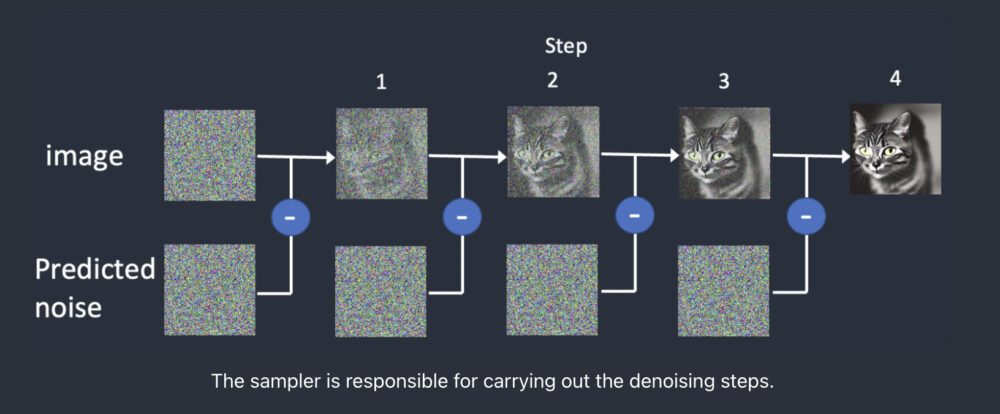
引用URL:https://stable-diffusion-art.com/samplers/
これらのノイズ除去のプロセスを「サンプリング」と呼んでいます。
そして、サンプリングに使用される手法のことを、「サンプラー」または「サンプリング方法」と呼びます。
ノイズを除去する方法によって(つまりはサンプラーによって)、最終的に出来上がる画像が変化します。
17種類のサンプラー
SeaArtでは17種類のサンプリング方法(サンプラー)があります。
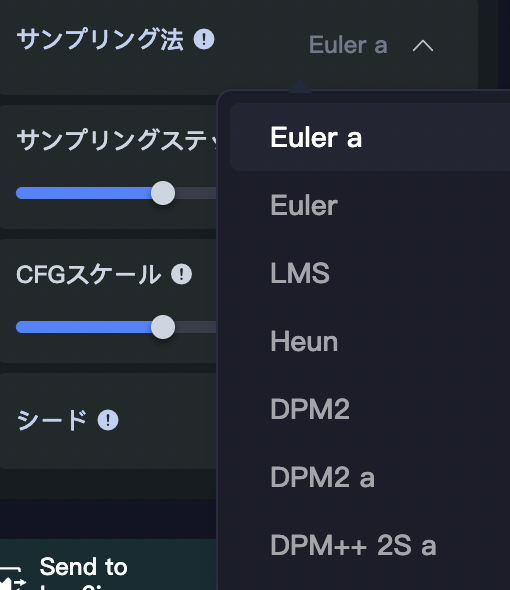
「サンプリング法」をクリックすると、17種類のサンプラーからひとつを選択できます。
Ancestral samplers について
- Euler a
- DPM2 a
- DPM++ 2S a
- DPM2 a Karras
- DPM++ 2S a Karras
サンプラーのうち上記のものは、Ancestral samplerと呼ばれています。
「Euler a」などの「a」は「Ancestral」を意味しています。
つまり、「a」が付くサンプラーはAncestral samplerです。
Ancestral samplerの特徴は、ノイズを除去するプロセス毎(ステップ)に、画像が大きく変化することです。

引用URL:http://mccormickml.com/2023/04/11/choosing-stable-diffusion-sampler/
上の画像では、「Eular」はステップの増減があってもイラストに大きな変化はありません。
一方で、Ancestral samplerである「Eular a」では、ステップ毎にイラストに大きな変化が見られます。
Ancestral samplerを使用すると再現性が得られにくくなります。
Karrasについて
- LMS Karras
- DPM2 Karras
- DPM2 a Karras
- DPM++ 2S a Karras
- DPM++ 2M Karras
- DPM++ SDE Karras
上記のように「Karras」が付いているサンプラーがあります。
「Karras」は、そのサンプラーを改善したものです。
ノイズが減ったり、シャープな画像になるようです。
各サンプラーの特徴
下表はSeaArtのサンプラーの簡単な特徴についてまとめてあります。
| サンプラー名 | 特徴 |
| Euler a | 「Euler」よりも速く、他のサンプラーよりも速い。精度が低め。 |
| Euler | 「Euler a」より遅いが、ほとんどのサンプラーよりは速い。精度は低め。 |
| LMS | 精度が高いが、遅い。 |
| Heun | 精度の点でEularを改良しているが、遅い。 |
| DPM2 | 精度が高いが、遅い。 |
| DPM2 a | DPM2 とほぼ同じだが、キャラクターのクローズアップが可能。 |
| DPM++ 2S a | リアルな質感が特徴的。 |
| DPM++ 2M | シャープな画像になりやすい。 |
| DPM++ SDE | シャープでな画像になりやすい。 |
| DPM fast | ステップ数が低いと絵が崩壊する。 |
| LMS Karras | 「LMS」の改良版。 |
| DPM2 Karras | 「DPM2」の改良版。 |
| DPM2 a Karras | 「DPM2 a」の改良版。 |
| DPM++ 2S a Karras | 「DPM++ 2S a」の改良版。 |
| DPM++ 2M Karras | 「DPM++ 2M」の改良版。精度が高く、速度もはやい。 |
| DPM++ SDE Karras | 「DPM++ SDE」の改良版。緻密な画像を生成できる。 |
| DDIM | x AND x 構文は使用不可。 ステップごとの速度は非常に速いが、多くのステップが必要。高いステップで良い画像が生成されやすい。 |
よく使われているサンプラー
- Euler a
- DPM++ SDE Karras
- DPM++ 2M Karras
- DDIM
以上4つのサンプラーが一般的によく使用されているようです。
まず「Euler a」で画像の出来を確認して、良さそうであれば精度が高いサンプラーを使用すると効率的です。
サンプリングステップについて
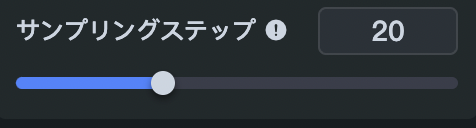
さきほど述べたように、ステイブル・ディフュージョン(Stable Diffusion)では、画像を生成するプロセスとしてノイズの除去を行います。
「サンプリングステップ」を簡単に説明すると、「ノイズ除去を行う回数」です。
サンプリングステップ数が増えると、より詳細な画像が得られますが、それに応じて計算時間も増加します。
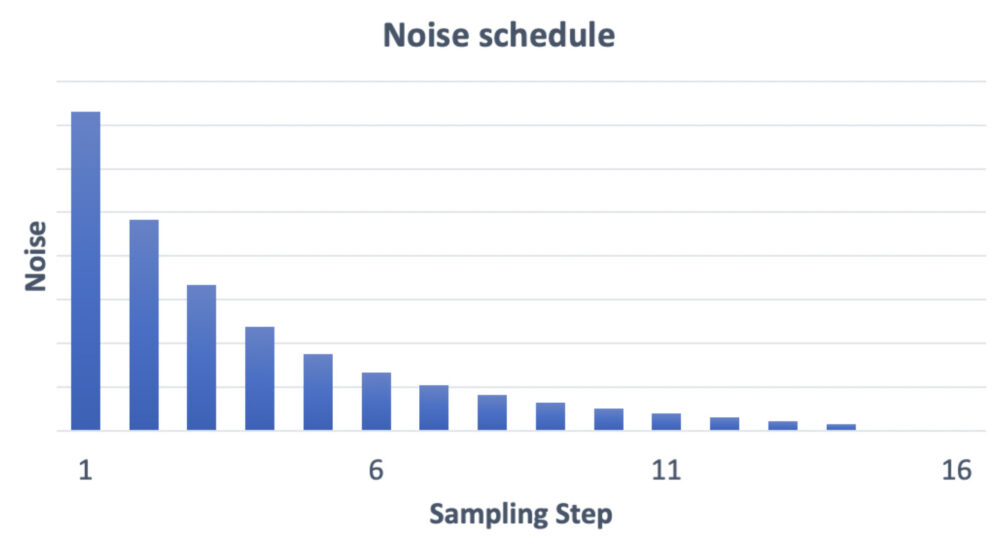
引用URL:https://stable-diffusion-art.com/samplers/
上図は横軸にサンプリングステップ数、縦軸にノイズ量をとったグラフです。
サンプリングステップの回数ごとに、ノイズが減っていき、最終的にはノイズが0になって画像が完成します。
上図はサンプリングステップ数を15に設定しているため、15回のステップでノイズが0になっています。
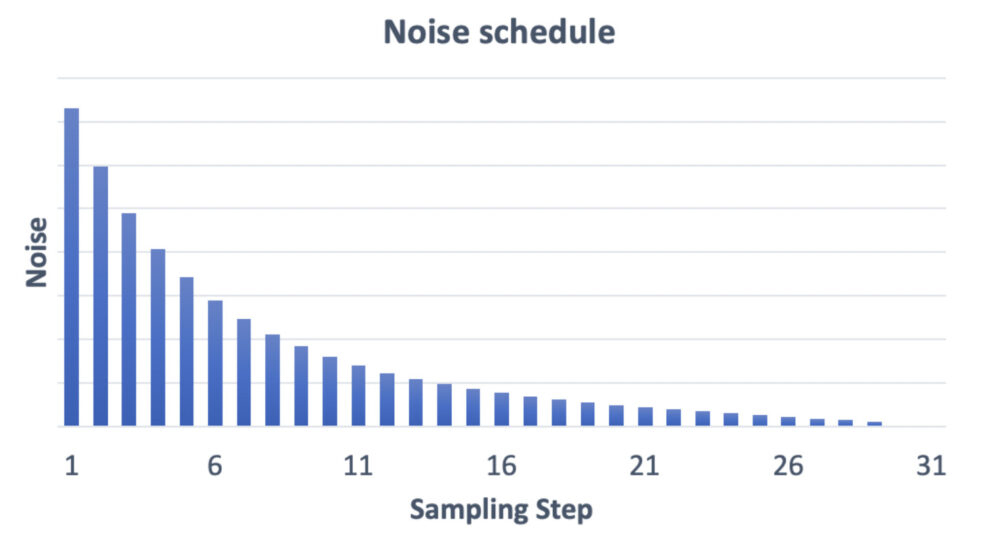
引用URL:https://stable-diffusion-art.com/samplers/
一方、上図はサンプリングステップ数を30に設定したグラフです。
ステップ数を15に設定したものと比較すると、ステップ間のノイズ減少量が少なくなっています。
このことにより、サンプリングの精度を高めることが出来ます。
基本的には、サンプリングステップは15以上が推奨されています。デフォルト値は20です。
各モデルやサンプラーで推奨ステップ数が異なりますので、各公式サイトなどをご参照ください。
CFGスケールについて
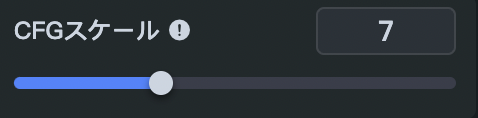
CFG(Classifier Free Guidance)スケールとは、入力したプロンプトと生成される画像の一致度です。
デフォルト値は7です。
- 高数値→プロンプトに忠実な画像が生成されるが、生成画像が崩壊することもある。
- 低数値→プロンプトを無視した独創的な画像になりやすいが、絵がぼやけることがある。
以上のように、CFGスケールの高低で画像の質が変化します。
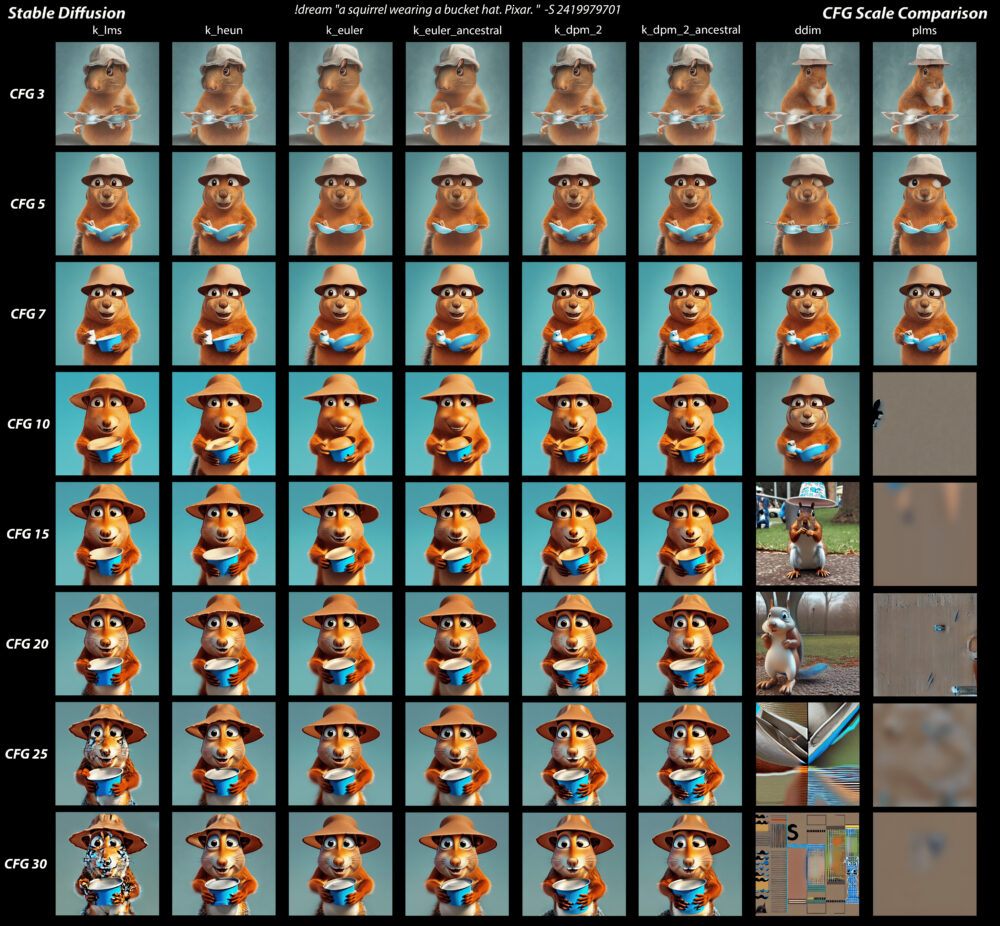
上図はCFGスケールを3-30までに設定した際の画像です。
CFG3-5では画像がボヤけていて、25以上になると画像が崩れているものが増えてきます。
各モデルやサンプラーで推奨CFGスケール値が異なりますので、各公式サイトなどをご参照ください。
シードについて

シード(Seed)値とは、画像に割り振られた固有番号のようなものです。
シード値1なら1の、100000なら100000の画像があらかじめ決められています。
例えばシード値を100に固定して画像を生成すると、毎回同じような画像が出力されます。
それは、シード値100の画像がすでに決められているからです。
SeaArtのシード値は、デフォルトでは「-1」に設定されています。
シード値「-1」の場合は、画像を生成するたびにランダムなシード値を取ります。
シード値がランダムな値を取ると、毎回違った画像が出力されることになります。

上の画像はシード値100で、プロンプトは「(傑作、最高品質) 犬」で生成しています。
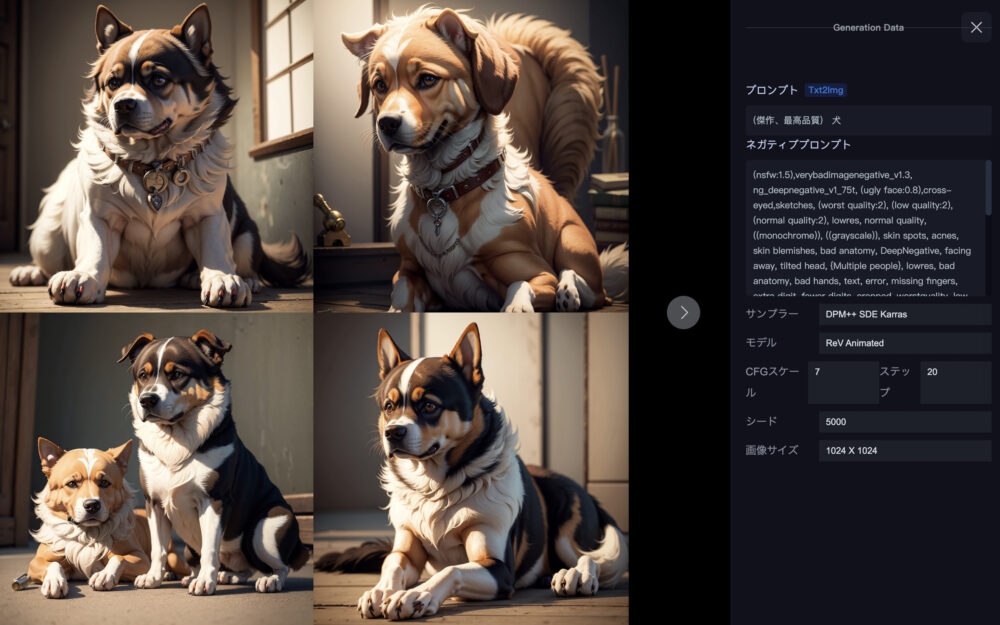
上の画像はシード値5000で、プロンプトは「(傑作、最高品質) 犬」で生成しています。
同じプロンプトでも、シード値が違えば画像内容も異なっています。
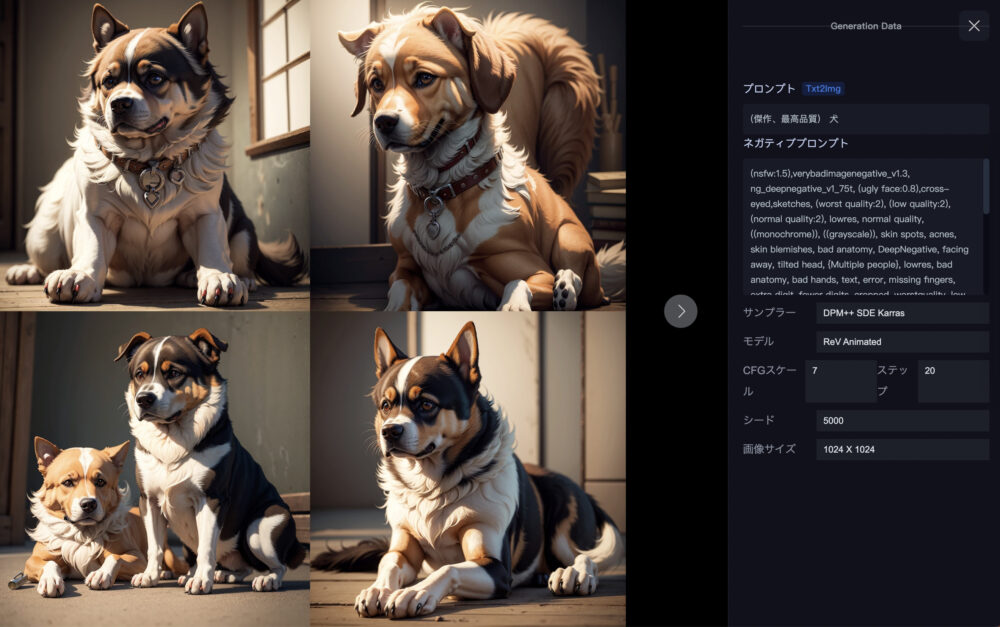
そして、上の画像がシード値をさきほどと同じ5000にして、同じプロンプトで生成しています。
シード値が同じであれば、2つの画像の間にはほとんど違いがありません。
コントロールネットについて
SeaArtのコントロールネットについて解説していきます。
コントロールネット(ControlNet)とは、アップロードした画像から情報を抽出して、様々な形で画像を調整する機能です。
コントロールネットの場所について
コントロールネットの場所について解説します。
左サイドバーの「Advanced」をクリックします。
そうすると、「コントロールネット」という項目が現れますので、そこからコントロールネットを実行できます。
もしくは画像生成画面(Generate画面)の右下にある、「Send to ControlNet」をクリックしても大丈夫です。
コントロールネットの使い方
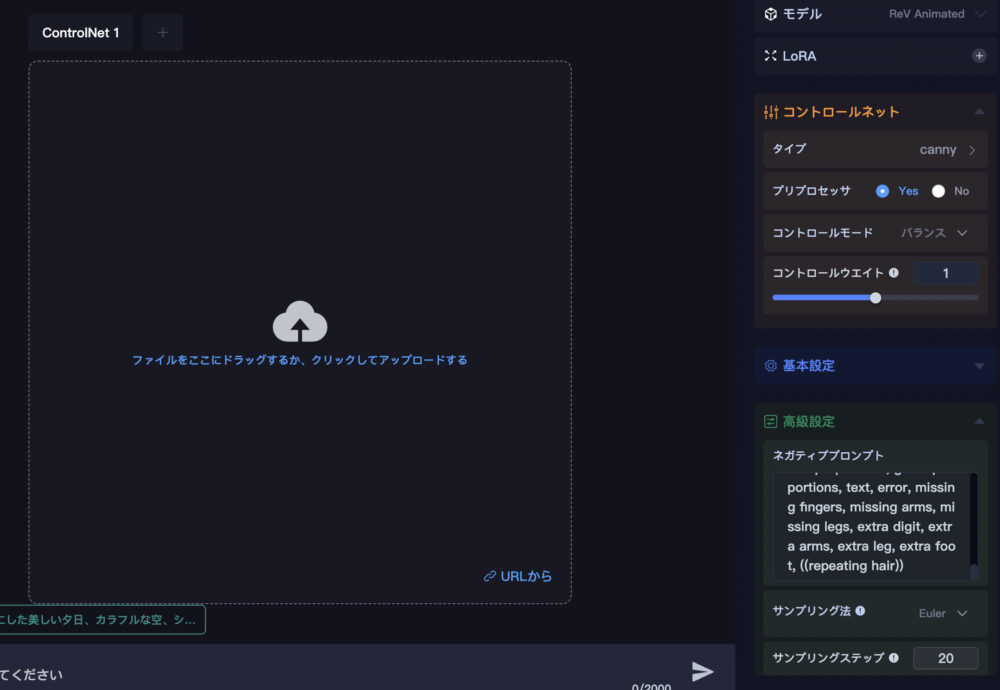
コントロールネット画面に遷移すると、このような表示になります。

この中央のボックスに自身のフォルダから画像をアップロード出来ます。
その画像を元に、コントロールネットで情報を抽出していきます。
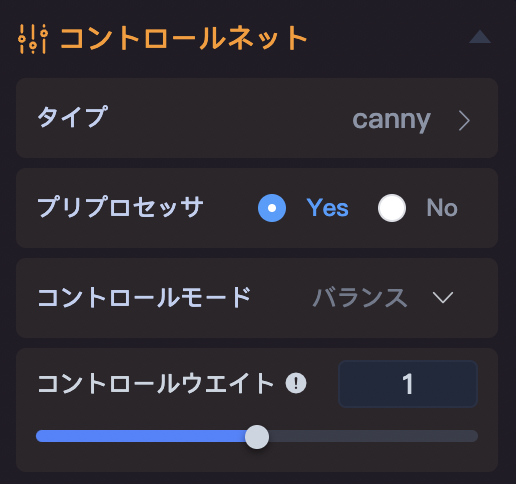
右サイドバーにコントロールネットの項目があります。
「タイプ」をクリックします。

「タイプ」をクリックすると、たくさんのコントロールネットのタイプモデルが表示されます。
各タイプについて解説していきます。
※基本的には下の画像をアップロードして使用します。

canny

コントロールネットの「canny」は、アップロードされた画像の線画情報を抽出します。
アップロードされた画像の色を変える時に役立ちます。
この画像をアップロードして、プロンプトに「金髪」とだけ入れてコントロールネットを実行します。

そうすると、構図はほぼそのままに、髪色が黒から金色へと変更されています。

抽出されたデータは上図のようになります(後述するPreview機能で再現)。
openpose_full

openpose_fullは、コントロールネットの中で最も有名なものだと思います。
アップロードした画像のポーズを元に、新たな画像を生成してくれます。
この画像をアップロードして、プロンプトは「老人」と入れてコントロールネットを実行します。

すると、さきほどの女性と似たポーズをした老人の画像が生成されました。
性別や年齢、衣服や髪型をプロンプトで変更しつつも、ポーズのみを保持することが出来ます。
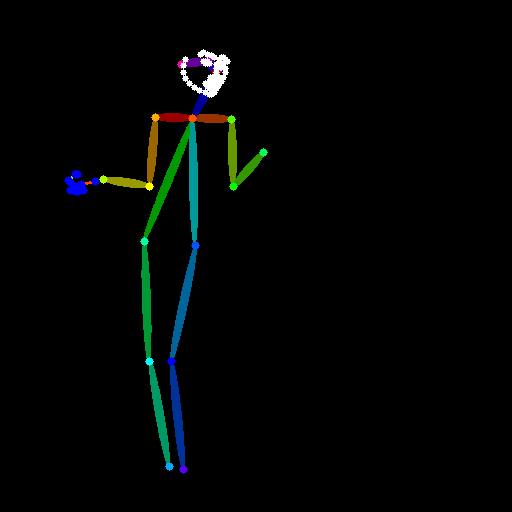
抽出されたデータは上図のようになります(後述するPreview機能で再現)。
lineart

lineartは、アップロードした画像の線画情報を抽出します。
cannyと似ています。
lineartは大まかな手書き風の線で描画されます。
この画像をアップロードして、プロンプトは「赤い服」にします。

構図は同じままで、衣服などが赤くなりました。

抽出されたデータは上図のようになります(後述するPreview機能で再現)。
lineart_anime

lineart_animeは、アップロードした画像の線画情報を抽出します。
lineartと似ていますが、アニメ風の塗りを行います。
この画像をアップロードして、プロンプトは「ピンク色の髪」にします。

全体的にピンク色になってしまいましたが、塗り方は少しアニメっぽい感じになりました。

抽出されたデータは上図のようになります(後述するPreview機能で再現)。
depth

depthは、アップロードした画像の奥行きの情報を分析して、新たな画像を生成することが出来ます。
openpose_fullと出力結果は似ていますが、少し違う結果になります。
openpose_fullは人体の骨と関節を抽出しますが、

depthは画像の奥行き情報を抽出します。
そのため、openpose _fullでは、骨格以外の部分(たとえば髪型など)や人体の重なり等をトレースすることが苦手です。
一方でdepthは画像のシルエットや奥行きの情報を抽出するため、髪型などもトレースすることが出来ます。
この画像をアップロードして、プロンプトを「金髪」と「老人」をそれぞれ別に入力してみます。

プロンプト「金髪」です。
cannyと同じように、色だけを変えることも可能です。

プロンプト「老人」です。
ポーズを維持したまま老人の姿を描くことが出来ます。
また、シルエットもほとんど変わらず描くことが出来ます。
normal_bae
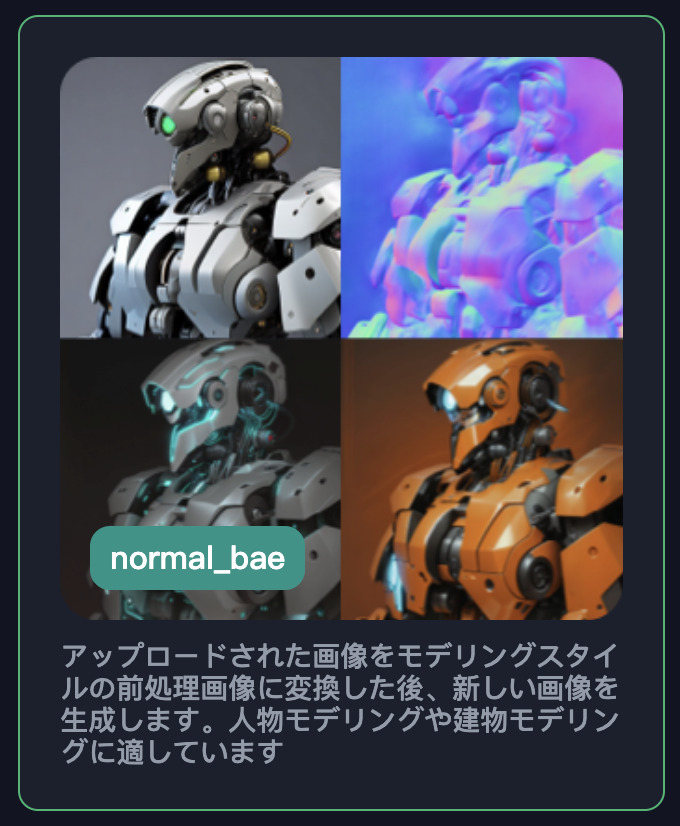
normal_baeは、法線マップを生成して、その情報を元に新たな画像を生成します。
法線マップは立体面・輪郭線として有効に機能するため、シルエット情報などをトレースすることが出来ます。
この画像をアップロードして、プロンプトを「笑顔」にします。

シルエットはある程度保持されたまま、表情が笑顔になっています。

抽出されたデータは上図のようになります(後述するPreview機能で再現)。
segmentation
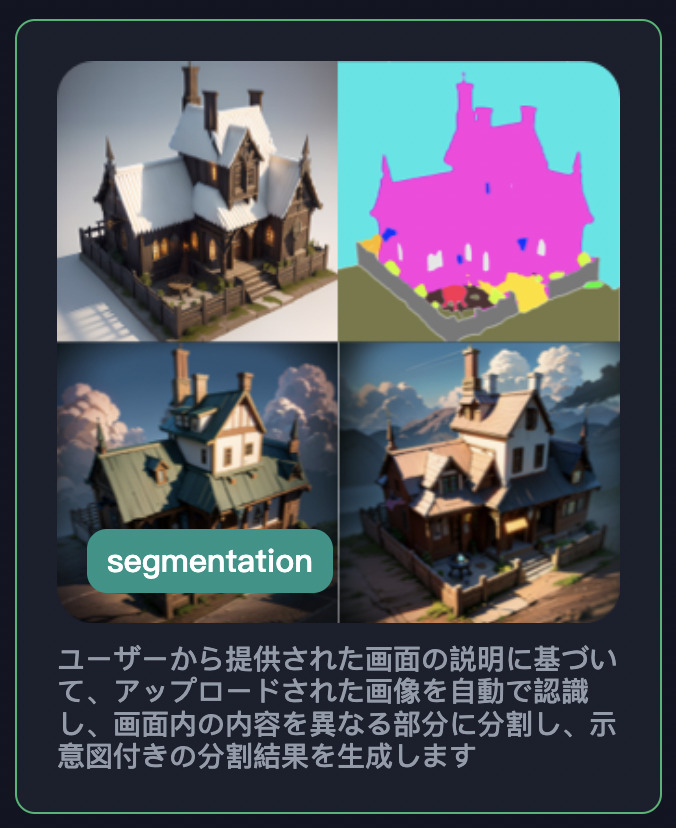
segmentationは、アップロードされた画像パーツを分割して抽出することが出来ます。

上図のように、建物の塀や屋根、空の部分などのパーツ毎に色分けされて抽出されます。
この画像をアップロードして、プロンプトを「(傑作、最高品質) 女性 全身 左手にペットボトルを持っている」にします。

左手に持っているグラスをペットボトルに変えたかったのですが、他のパーツも変わってしまいました。
使いこなすのは難しそうな印象です。
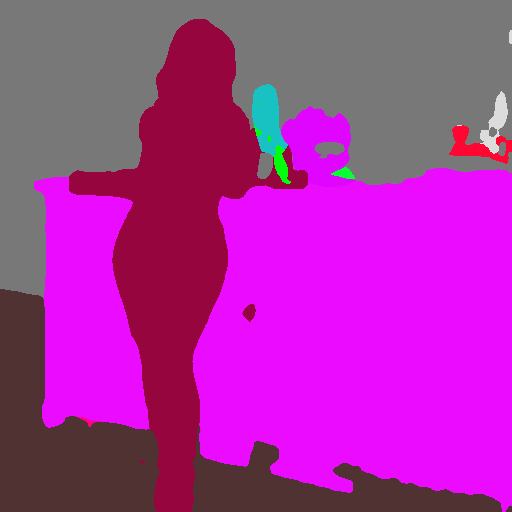
抽出されたデータは上図のようになります(後述するPreview機能で再現)。
tile_resample

tile_resampleは、全体的な画質を向上させることができます(これを行っただけではアップスケールは出来ません)。

この画像をアップロードして、画面下の「Intelligent Analysis」をクリックします。

アップロードした画像を参照にして、上図のようなプロンプトが自動で書き込まれますので、これを送信します。

出来た画像がこれになります。
画像が補正されています。
mlsd

mlsdは、建造物の直線の線画情報を抽出します。
よって、人体のような曲線がある対象物に対しては効果がありません。

この画像をアップロードして、プロンプトを「和室」にしてみます。

元の部屋にあったオブジェクトの情報が引き継がれており、構図としては元画像を踏襲できています。
scribble_hed

scribble_hedは、落書きのようなラフ画をアップロードして、それを元に綺麗な画像を生成することができます。

このようなラフな画像をアップロードします。プロンプトは「困った顔をした老婆」です。

そうすると、それらしい画像を生成してくれました。

抽出されたデータは上図のようになります(後述するPreview機能で再現)。
hed_safe

hed_safeは、アップロードされた画像の輪郭線を詳細に抽出します。
cannyよりもより細かい線を抽出出来ます。
この画像をアップロードして、プロンプトを「靴下を履く」にしました。

靴下を履くことが出来ています。

抽出されたデータは上図のようになります(後述するPreview機能で再現)。
color_grid

color_gridは、アップロードした画像を一旦モザイクにして、その状態でカラーや位置情報を抽出することが出来ます。
モザイクにした情報ですので、新たに画像生成した際には、元画像と構図が異なることがあります。
この画像をアップロードして、プロンプトを「女性」にします。

出来た画像がこれになります。
ポーズなどが元画像と異なっているものを作れます。
抽出されたデータは上図のようになります(後述するPreview機能で再現)。
shuffle

shuffleは、アップロードした画像を激しく曲げて、再構築することが出来ます。
さきほどご紹介したcolor_gridと似ていますが、shuffleのほうがより元画像とかけ離れた画像を生成できます。
この画像をアップロードして、プロンプトを「女性」にします。

出来た画像は、このようにいびつな状況になりました。
ランダム要素が欲しい場合にはshuffleもありなのかもしれません。

抽出されたデータは上図のようになります(後述するPreview機能で再現)。
参考生成

「参考生成」は、アップロードされた画像の人物、キャラクター、物品などを参考に、類似する新しい画像を生成します
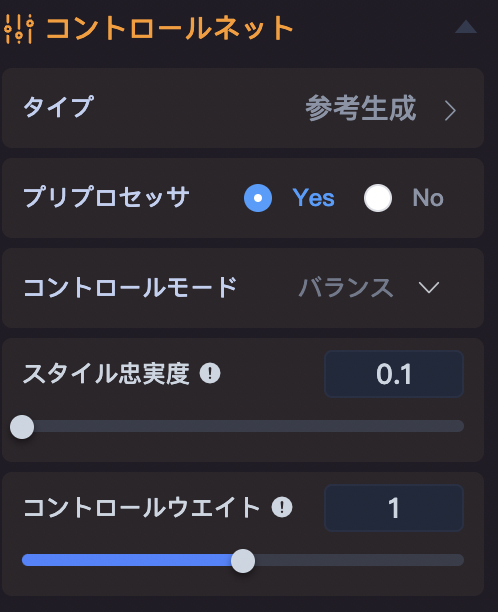
「参考生成」を使用する際には、「スタイル忠実度」という項目が表示されます。
「スタイル忠実度」は「参考生成」の特有機能です。
この値が高いほど、アップロードした画像の再現性が増します。
画像をアップロードして、画面下の「Intelligent Analysis」をクリックします。
アップロードした画像を参照にして、上図のようなプロンプトが自動で書き込まれますので、これを送信します。
「スタイル忠実度」は0.8に設定しました。

上画像が完成しました。
このように、元画像と類似した画像を作成することが出来ます。
コントロールネットを組み合わせる
コントロールネットを複数組み合わせることが可能です。
今回は部屋の画像と、人物の画像を組み合わせてみたいと思います。

まずはコントロールネットに1枚目の画像をアップロードします。
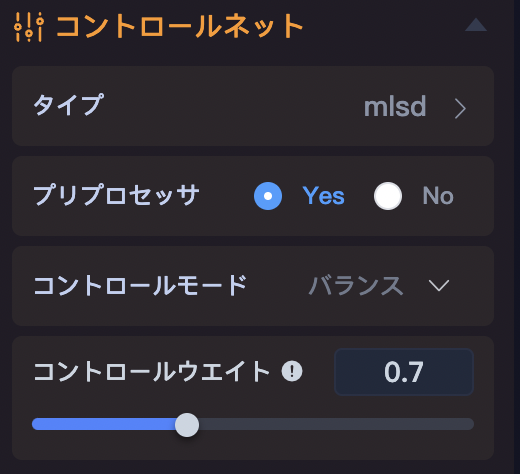
この画像は部屋の画像であるため、mlsdを採用しました。
そして、コントロールウェイト(コントロールネットの強度)を少し下げて0.7に設定しました。

そして、「ControlNet 1」の右にある「+」マークを押します。
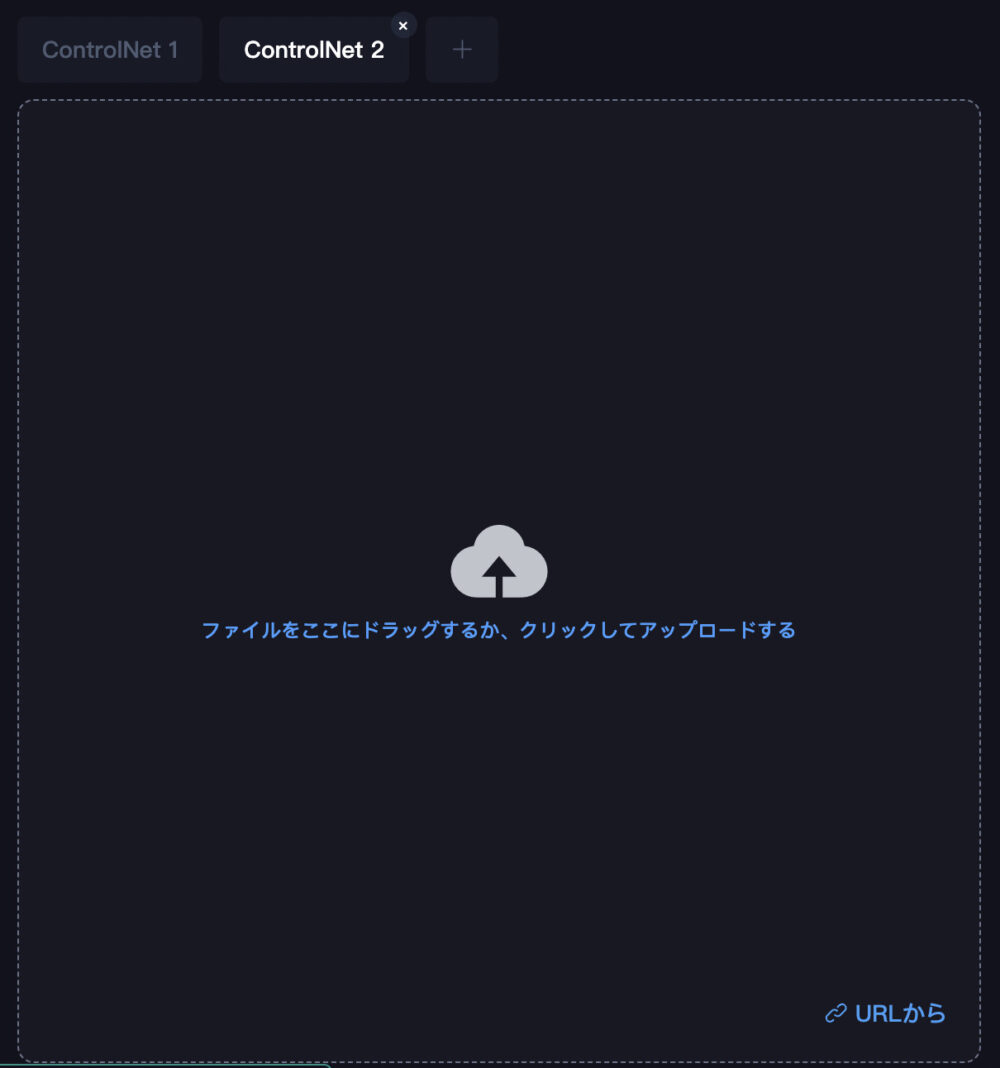
すると、「ControlNet 2」のタブが生成されて、新たに画像をアップロードできるようになります。
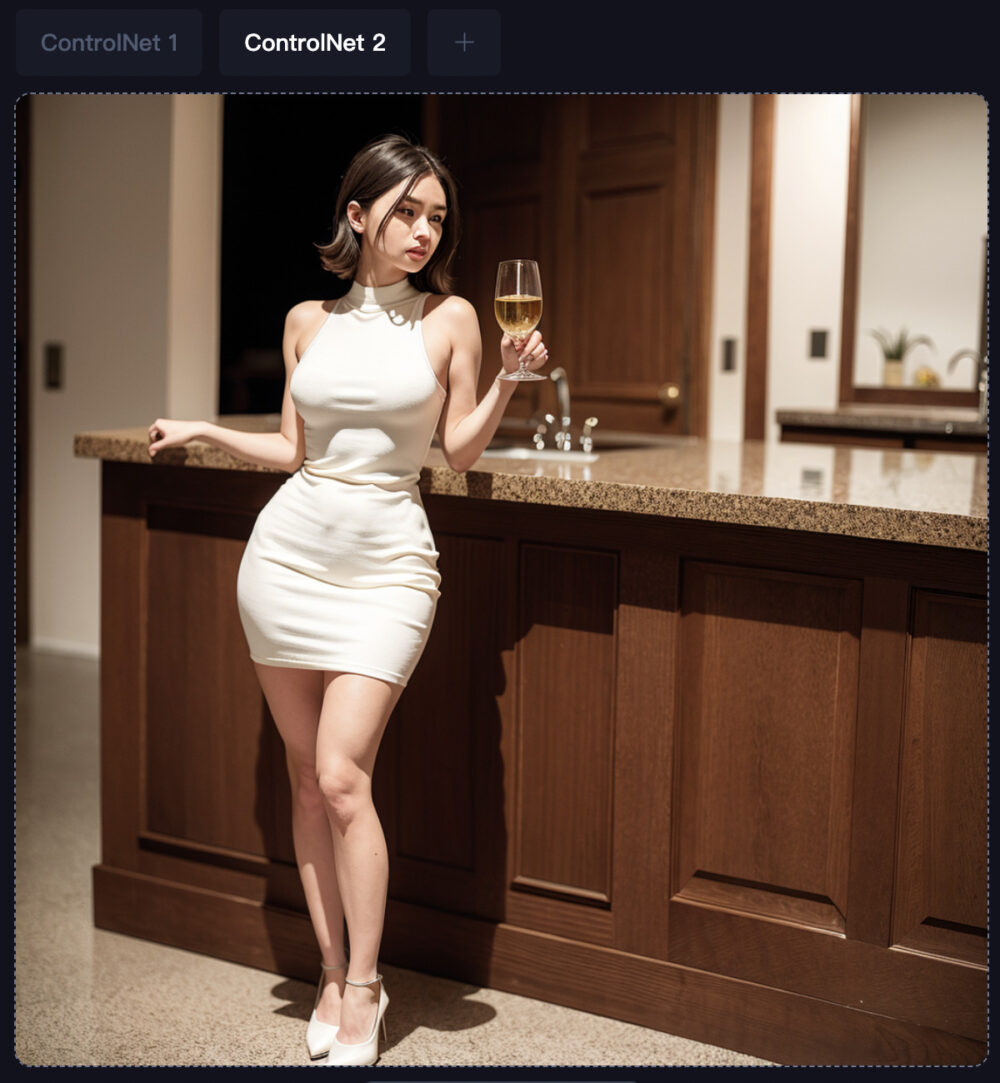
「ControlNet 2」にも画像をアップロードします。
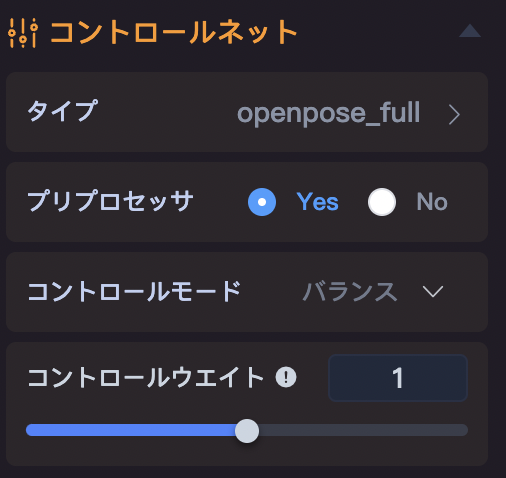
人物のポーズのみのデータが欲しいので、openpose_fullを採用しました。
コントロールウェイトはデフォルトの1に設定します。

そして、プロンプトは部屋に立つ女性にしました。

出来た結果が上図になります。
部屋の構図と、人物の構図は元画像に沿ったものが出来ていると思います。
このように、コントロールネットを複数使用して、それぞれの特徴を活かしてデータを抽出して、合成することも可能です。
Expansionについて
Expansionについて解説していきます。
Expansionは「拡張」という意味があり、画像の枠外をAIが自動で作成してくれる機能です。
いわゆる「アウトペインティング機能」です。

ツール→「Expansion」をクリックします。
この画面が表示されますので、画像をアップロードしましょう。
※ただし、画像サイズは1024×1024以下でなければなりません。
今回はSeaArtで作成した上図の画像をアップロードしました。
画像サイズは512×512です。

このように、画像の外枠をひっぱることで、自由な比率で画像を拡張することができます。

元画像のイメージを保ったまま画像を拡張したい場合は、「Intelligent Analysis」をクリックします。
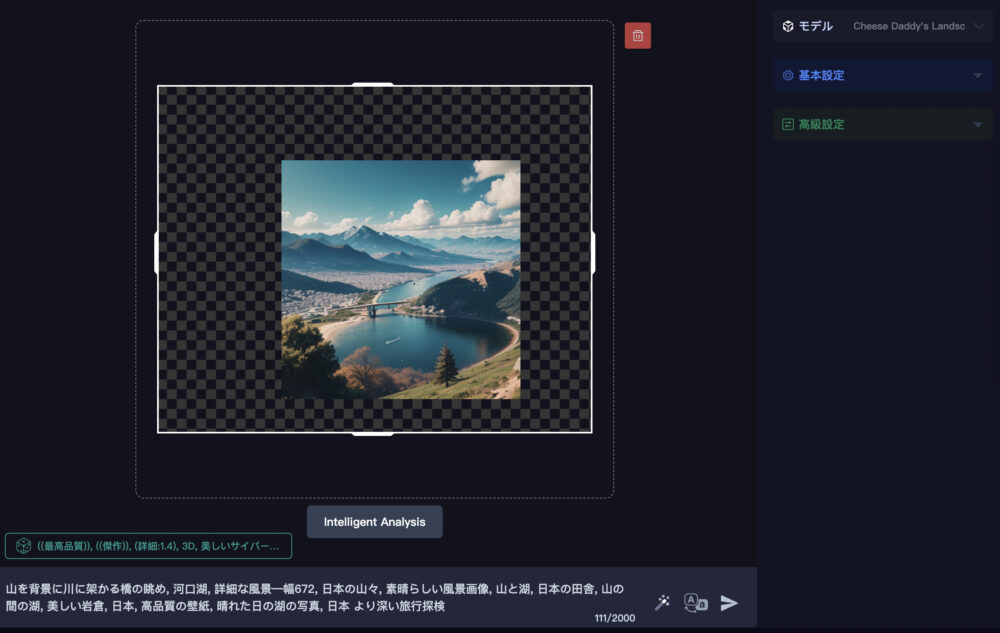
そうすると、元画像のイメージに合ったプロンプトを生成してくれます。
モデルも自動で設定してくます。
この状態で紙飛行機ボタンを押して実行します。

拡張された画像が生成されました。

元画像はこれです。
特に違和感なく拡張されていると思います。
プロンプトでイメージを変える
さきほどは「Intelligent Analysis」を使用して、元画像と同じイメージで画像を拡張しました。
今回は元画像のイメージとかけ離れたプロンプトを使用して画像を拡張してみます。

この画像の外枠の上と横を大きく広げます。

プロンプトは「空から大きなトマトが降ってくる」にしてみました。

出来た画像が上図になります。
空からトマトが降ってきていて、元画像の穏やかなイメージが一変して、シュールな雰囲気になりました。
このように、プロンプトを指定することで、画面外の生成内容をコントロールすることも可能です。
アップスケールについて
アップスケールとは、画像の解像度を高くすることです。
解像度が低いと、拡大するとぼやけて見えることがあります。
解像度が高いと、拡大しても鮮明な画像になります。
SeaArtで生成した画像をアップスケールする方法やアップスケーラーについて解説していきます。
アップスケールする方法
画像をアップロードしてアップスケールする
左サイドバーに「アップスケール」の項目がありますので、それをクリックします。

このような画面になりますので、ファイルをアップロードします。
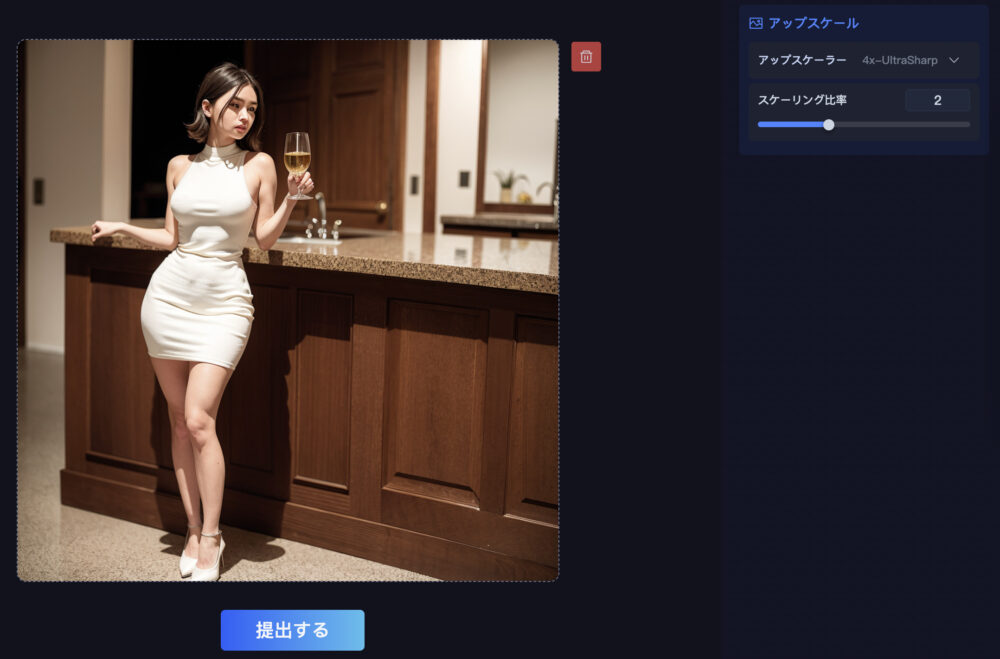
女性の画像をアップロードしました。
画面下の「提出する」を押すと、アップスケールが開始されます。
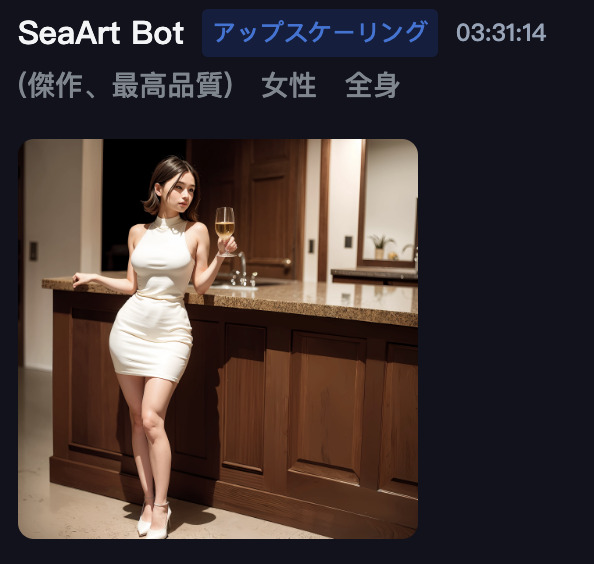
画像生成画面(Generate)にアップスケールされた画像が表示されます。
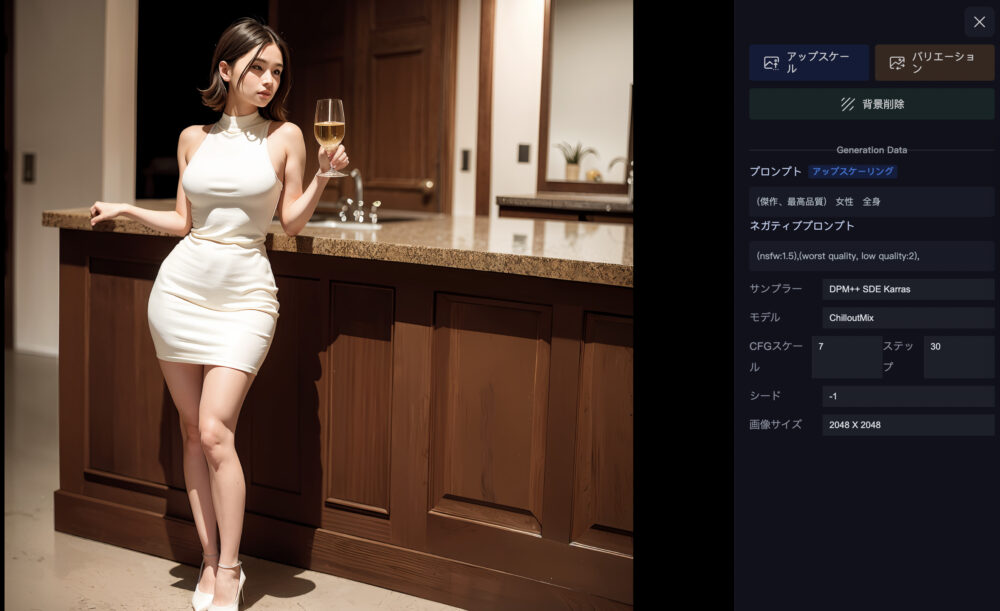
それをクリックすると詳細な情報が確認できます。
画像サイズが「2048×2048」へ拡大されていることが分かります(元画像は1024×1024)。
生成画像からアップスケールする方法
生成した画像からそのままアップスケール方法もあります。

上図は画像生成画面(Generate)で表示された画像です。
この画像をクリックします。
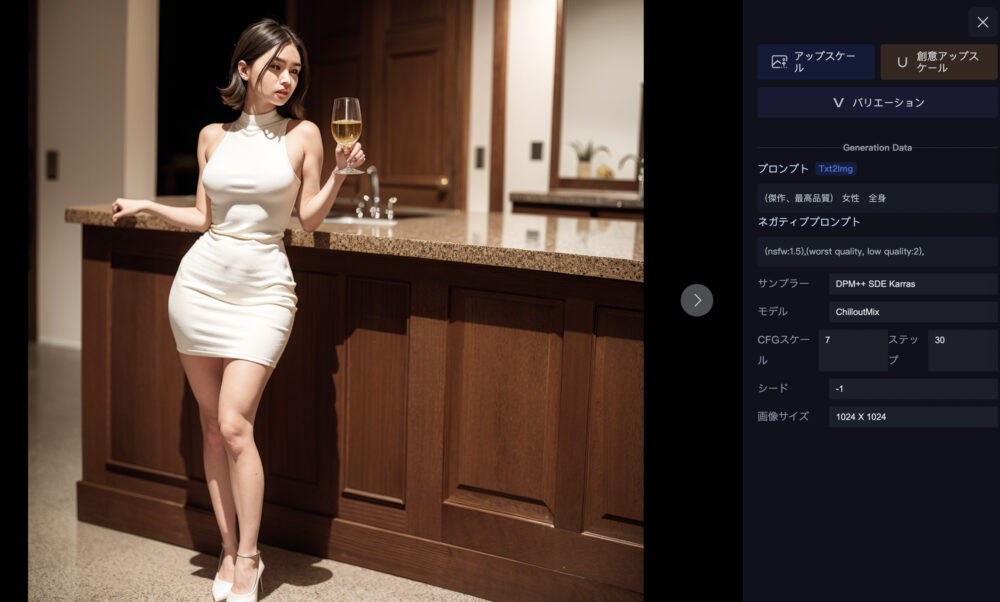
そうすると上図の表示になります。
画面右上に「アップスケール」と「創意アップスケール」という項目があります。
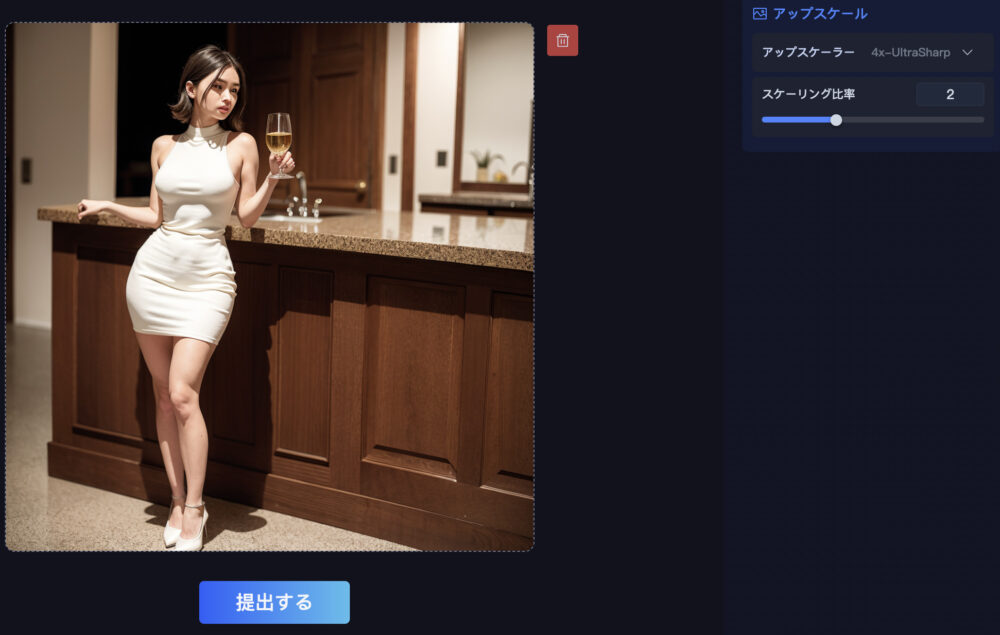
「アップスケール」を押すと、アップスケール画面に遷移しますので、「提出」をクリックするとアップスケールされます。
創意アップスケールについて
戻って、「創意アップスケール」をクリックしてみます。
クリックすると、即座に画像生成が始まります。

「創意アップスケール」で作成された画像です。
「創意アップスケール」は、よりクリエイティブな効果を生み出すアップスケールです。

上図は普通のアップスケール(4x-UltraSharpを使用)です。

上図は「創意アップスケール」でアップスケールした画像です。
顔や各パーツが補正されていることが分かります。
一般的に綺麗に見える画像を作ることが「創意アップスケール」では可能です。
また、前述しましたが「創意アップスケール」をした後の画像は、「背景削除」やさらなる「アップスケール」、「バリエーション」を行うことも出来ます。
アップスケーラーについて
アップスケール画面の右サイドバーに「アップスケーラー」という項目があります。
アップスケーラーとは、解像度を上げるためのアルゴリズムや技術のことです。
アップスケーラーの種類によって、アップスケール後の仕上がりに違いが生じる場合があります。
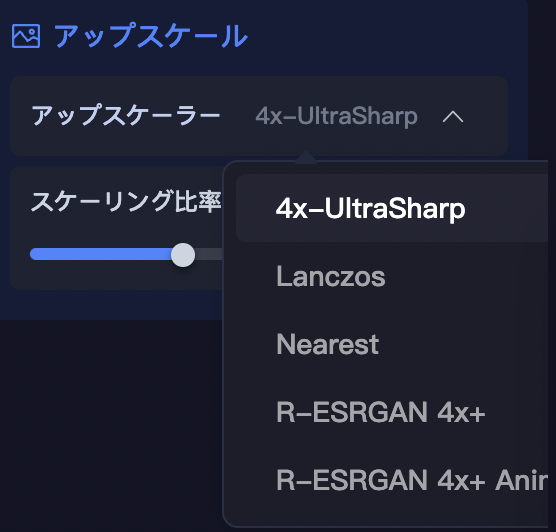
SeaArtのアップスケーラーは以下の5種類あります。

4x-UltraSharp

4x-UltraSharpでアップスケールしました。
高品質なアップスケーラーとして知られています。
SeaArtのアップスケーラーのデフォルトに設定されています。
Lanczos

Lanczosでアップスケールしました。
エッジが鮮明に描写されます。
Nearest

Nearestでアップスケールしました。
処理速度が速い傾向にありますが、画質低めです。
R-ESRGAN 4x+

R-ESRGAN 4x+でアップスケールしました。
写実的画像に特に対応しています。
R-ESRGAN 4x+ Anime6B

R-ESRGAN 4x+ Anime6Bでアップスケールしました。
アニメ画像に特に対応しています。
画像情報について
SeaArtの機能である「画像情報」について解説します。
左サイドバーの「ツール」→「画像情報」をクリックします。
上図の表示となります。
ファイルをアップロードします。
部屋の画像をアップロードしました。
画面下の「提出する」をクリックします。
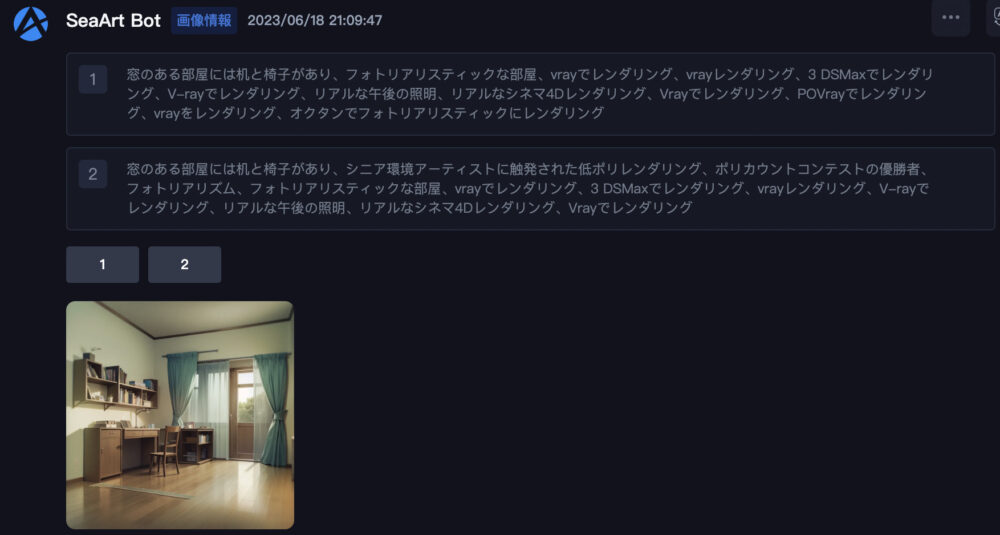
そうすると、上図のように画像に対応したプロンプトが2種類表記されます。
ボタンが「1」「2」の2つ用意されています。
「1」のボタンを押してみます。
ボタンを押すと、「AI広場」に遷移します。
検索バーにはさきほど表記されていたプロンプトがペーストされています。
そのプロンプトを用いて、画像が検索されて、他人が作った画像が一覧表示されています。
「画像情報」の機能を使うことにより、アップロードした画像と似た画像を探すことが出来ます。
Previewについて
Preview機能について解説します。
これはコントロールネットのデータ抽出を可視化する機能です。
左サイドバーの「ツール」→「Preview」をクリックします。
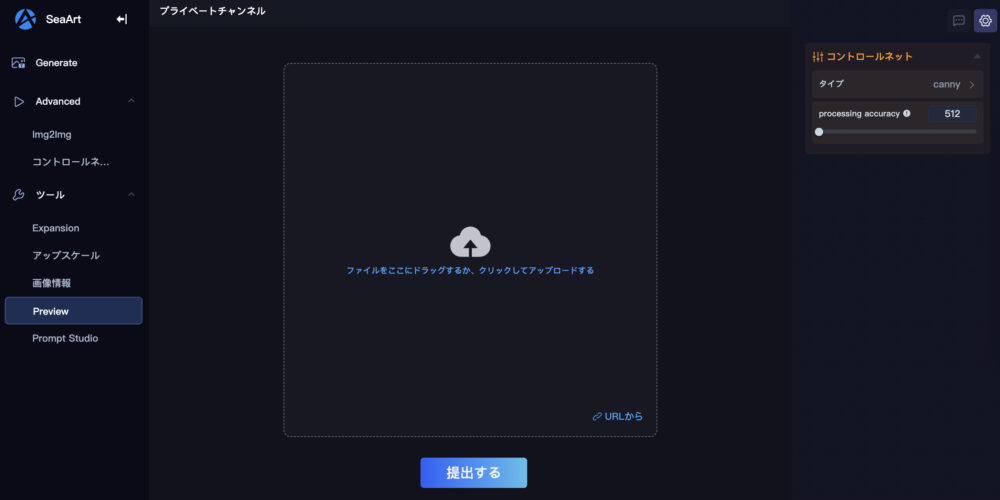
上図の画面になります。
コントロールネットに用いる画像をアップロードします。
画像をアップロードしました。
画面右上でコントロールネットの種類を選択できます。
今回はデフォルトの「canny」のままで「提出する」をクリックします。
「提出する」をクリックすると、画像生成画面(Generate)にて、上図のような画像が生成されます。
これは、元画像から線画情報を抽出したものです。
このように、「Preview」機能を使うと、コントロールネットの抽出データを確認することができます。
Prompt Studioについて
「Prompt Studio」について簡単にご紹介します。

左サイドバーの「ツール」→「Prompt Studio」をクリックします。
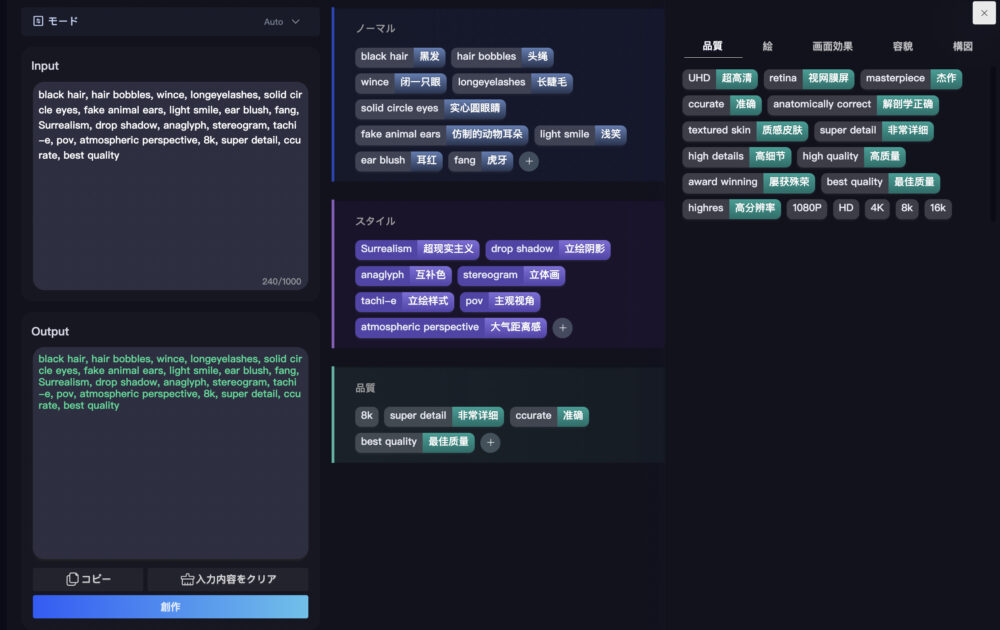
上図のような表示になります。
画面中央と右側の各項目をクリックすると、左下の「Output」欄にプロンプトが反映されます。
様々な項目がありますので、各自ご確認ください。
画面左下の「創作」ボタンを押すと、「Output」欄のプロンプトを用いて画像が生成されます。
「Prompt Studio」の使い勝手は良いとは言い難いですので、外部サイトでプロンプトを組み立てるといいかもしれません。
NSFWについて
SeaArtで画像を生成していると、右図のように「NSFW」と表記された画像が生成されることがあります。
「NSFW」とは、Not safe for work の略語で、「職場で見るのは危険」という意味があります。
つまり、アダルト・暴力・グロ画像など、公の場で閲覧・アクセスするのに適さないものを指します。
NSFWを解除する方法について

SeaArtにおいて「NSFW」と判断されれば、その画像は非表示となり、グラデーションのみが掛かった状態になります。
2023年6月19日時点では、NSFWを解除する方法は見つかっておらず、その画像の内容を閲覧することが出来ません。
課金システムが開始されて、課金をすれば見られるようになる可能性もありますが、現時点ではどうすることも出来ないと思います。
NSFWの出現頻度を少し下げる

上の画像は「困った顔をした老婆」というプロンプトで画像生成しました。
しかし、4枚のうち1枚が「NSFW」と判断されて非表示になりました。
このように、全く意図せずに「NSFW」の画像が生成されてしまうことが多くあります。
これは、画像が少ない状態で生成されてしまうのと同じですので、タイムパフォーマンスの低下になります。

ひとつの対策として、ネガティブプロンプト欄に「NSFW」や「(((NSFW)))」の文字を記入することが挙げられます。
これにより、「NSFW」の画像が生成されることを抑制することが可能ですが、効果は完全とは言えないのが現状です。
商用利用について
SeaArtと作成した画像に関して、商用利用可能は原則として可能なようです。
以下は利用規約のコンテンツポリシーとコンテンツライセンスの引用文です。


お客様は、お客様がアップロード、投稿、公開、表示、または当社のサービス上またはサービスを通じて利用可能にしたコンテンツに対するすべての権利、所有権、利益を所有していること、またはそうする権利を有していることを表明および保証します。コンテンツはコンテンツ ポリシーに準拠する必要があることに注意する必要があります。
上記の条件に従い、お客様は他のユーザーに対し、当社のサービスを通じてお客様のコンテンツに基づく二次的著作物を作成するための、世界規模、永久、非独占、無料、ロイヤルティフリー、サブライセンス可能、取消不能なライセンスを付与するものとします。
お客様は、本契約により、当社および当社の関連会社に対し、お客様のコンテンツおよび当社のサービス上での派生作品を使用、表示するための、世界的、永続的、非独占的、無償、ロイヤルティフリー、サブライセンス可能、取消不能なライセンスを付与します。
上記のライセンスは、理由の如何を問わず、当事者による本契約の終了後も存続します。
以上のようになっています。
また、SeaArtの公式redditでは、
公式には商用利用は禁止されていませんが、それに伴うリスクは利用者自身が負担する必要があります。
と記載されています。
SeaArt公式では商用利用は禁止していませんが、使用するのは自己責任で、という感じでしょうか。
詳しいことは法律の専門家に尋ねてから商用利用した方が良いかもしれません。
まとめ
2023年6月19日現在、SeaArtは誰でも無料で画像を生成することが出来ます。
毎日80枚無料で作成できますが、ログインボーナスが50コインありますので、実質130枚無料で作成可能です。
アップスケール機能、コントロールネット機能、img2img機能、検索機能、豊富なモデルとLoRA、日本語プロンプト対応、すぐに始められることなど、初心者から中級者まで幅広く遊べる機能が満載です。
ぜひSeaArtを利用してみましょう。